
늦었지만 10월 14일 데이터야놀자 2023에서 들은 내용과 후기를 올려본다.

1. 데이터 유통 플랫폼 구축하기: 저장소를 통합하라
- Straw라는 데이터 플랫폼 개발
- 데이터 조회할 때, region을 나누어 각각에 partition 부여 (HashPrefixed). 테이블 생성시 미리 리전을 나눠 놓아 성능 개선
- Straw 도입 이전에는 조직별로 데이터 구성이 달랐음. 이제 통합화
- Airflow 기반으로 Strawflow를 개발. 동적으로 Airflow DAC 생성해 요청 처리. Airflow에서 Straw CLI 처리. 실행 과정은 Straw 들어가면 확인 가능
- 내가 원하는 데이터를 찾으려면 어떻게 하나? 물어물어 하거나, 사내위키 등 탐색
- 데이터 큐레이션 도구 개발 (데이터 사전 같이 생김)
2. 데이터 신뢰성 엔지니어링
- 코인원 데이터 엔지니어 (코인 거래소)
- 신뢰성 or 정합성
- 배경
- 웹개발 하다 DE 시작
- RDB → Redshift로 ETL 배치 제작, 외부 데이터 크롤링하여 적재 등
- 파이프라인 외부 고려x, 복구가 오래걸리는 파이프라인, 장애 내구성 낮은 등의 문제
- 정합성이 안 맞거나, 품질이 좋지 않아 사용자 이탈
- ETL → ELT
- 웨어하우스 변환 집계. Redshift → BigQuery
- 이 과정에서 dbt 도입. 변환 파이프라인 사용성 증가
- Datahub, Lightdash, Airbyte 등 도입
- 이미 신뢰를 잃었던 DW 사용자들에게 어떻게 신뢰성 다시 보장?
- 특정 테이블을 파이프라인으로 옮길 때
- 한 행은 불변한다는 전제 하에, 증분 적재하고 있었음
- 이후 데이터 오류가 있어, delete/update 필요성 생김
- 특히 코인원은 블록체인 데이터 특성상, tcp같이 깔끔하게 통신되지 않음. 파이프라인 내/외부적 장애요소 발생
- 파이프라인 만든 사람도 이런 상황을 예상할 수 없음
- 웹개발 하다 DE 시작
- EL 파이프라인 신뢰성
- SLA, SLO 등으로 판단
- SLA(서비스 수준 계약)
- 제공하는 서비스 유형, SLO(서비스 수준 목표), SLI(서비스 수준 지표) 정의. 목표 미달성 시 복구 프로세스, 보상 절차 포함
- 고객에게 제공되는 예: 오후 3시 이전 주문시, 내일 새벽 배송 보장!
- 오전 7시 이전 배송에 실패한 경우, 1000원 쿠폰 지급
- 팀 사이의 예: 데이터 팀에서 사내 DW 사용자에게 웨어하우스 제공. 제공한 만큼 데이터 팀의 성과로 사용
- EL 파이프라인 SLA
- 파이프라인 관점
- 제공하는 서비스 유형: 데이터 파이프라인
- SLO: 가용시간?
- SLO
- 사용 예상치 측정
- 테이블 정합성은 맞겠지? → 정합성 에러 발생확률 0.01% 미만 보장)
- 테이블이 빅쿼리에 제때 추가되겠지? → 테이블 업데이트 시각 - 배치시각을 N분 이내로 보장
- Airflow는 항상 잘 작동하겠지? → 가동시간 99% 보장
- 정합성 검사
- 일반적 방법
- count(*), pk 등 중요한 컬럼에 min, max, count group by 등
- 테이블을 dump(백업 DB) 해놓고, full join diff? 하기도 함
- 모든 열을 검사하는 도구: datadiff (Datafold에서 개발)
- pk 범위, 원하는 컬럼 범위 정의하고, 양쪽 DB(Redshift → Snowflake)에서의 행 id로 확인. 정합성이 깨진 row 탐색
- 일반적 방법
- 생존 분석
- 특정 사건이 발생하기까지 걸리는 시간 분석. 제품이나 생물의 수명 분포를 나타내는데 사용. time to event
- 경과시간에 따른 누적확률분포(cdf)
- 정합성 에러 발생을 event로 하면 time to event로 취급. 시간에 따른 정합성 에러 발생 확률
- 0.01% 확률로 정합성 에러가 발생하는 경과 시간에 정합성 검사 시스템 실행. 즉 0.01%가 되기 전에 검사 실행 → 모든 데이터의 0.01% 정합성 보장
- 시뮬레이션
- 데이터의 수명(정합성 에러 발생까지)을 그래프로 나타냄
- 0.01%가 되는 임계 시간(25시간)마다 정합성 검사 실행 → 모든 데이터의 0.01% 정합성 보장
- 기대한 것과 실제의 분포 차이: 에러 발생하지 않은 사건들 포함했기 때문?
3. 모수(1)가 충분히 크면(2) 중심극한정리(3)에 따라서 정규분포(4)라고 해도 되는 거 아니에요?
- 위 4개 단어에 대해서 다룸
- 모수
- 모집단의 수가 아님
- 사전적 의미: 모집단의 특성을 나타내는 값. 모평균, 모비율, 모분산, 모표준편차 등. 영어로는 Parameter
- 모집단: 관심 대상의 전체집합. 대한민국 국민, 우리 서비스 모든 사용자 등. 이 전체집합의 모든 요소를 조사하는 것은 시간과 비용이 많이 소요됨
- 표본: 모집단의 부분집합. 표본통계: 표본통계량을 이용해 모수 추정/추론
- 모수는 특정 숫자가 아님! 마케팅 캠페인 모수(x) 몇 명이에요 → 대상자(o) 몇 명이에요?
- 충분히 크다
- 마케팅할 때, 모수 충분해? 라는 질문을 던지곤 함
- 충분히 크다: 추측되는 어원은 큰 수의 법칙 (흔히 알고 있는 건 약한 법칙, 강한 법칙도 있음)
- 약한 법칙: (Xi(확률변수)가 iid일 때?) 표본의 크기가 충분히 크다면, 표본평균은 모평균에 가까워짐
- 예: 주사위 기대값은 3.5. 실제로 던졌을 때 시행이 클수록 3.5에 가까워짐
- 표본이 얼마나 커야 하는가?
- 30개면 크다? DAU 20만명이면, 보통 설문조사 대상자 수인 1,000명으로 해도 되나?
- 근데 누구도 알 수 없음
- 라플라스 정리 수학적으로 보면, n이 무한대로 감. 커질수록 좋을 뿐, 어떤 숫자에 도달해야 하는 건 아님
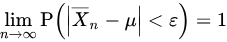
- 중심극한정리
- 동일한 확률분포를 가진 독립확률변수(iid) n개의 평균의 분포는 n이 충분히 크다면 정규분포에 수렴한다
- n은 표본의 사이즈가 아님. 추출 횟수일 뿐
- 표본 크기는 얼마나 커야 하는지, n이 몇 이상이어야 하는지는 역시 알 수 없음
- 동일한 확률분포를 가진 독립확률변수(iid) n개의 평균의 분포는 n이 충분히 크다면 정규분포에 수렴한다
4. 데이터로 셀럽과 팬의 마음을 측정하기
- 팬심(셀럽 후원 플랫폼)
- 팬심 M(Message): 메시지 보내기, 후원하기(셀럽은 수익 창출)
- 팬심 G(Gift): 팬이 선물 보내거나, 셀럽이 팬에게 선물 역조공
- 팬은 1:1 채팅(셀럽의 채팅만 보임), 셀럽은 1대다(모든 팬의 채팅 보임)
- 앱로그 데이터 수집(믹스패널, 빅쿼리) → 데이터 ETL(python) → 데이터 분석 → 대시보드 제작(태블로) → 메일링 & 피드백(stibee)
- 믹스패널은 빅쿼리 커넥터만 있으면 바로 데이터 가져올 수 있음
- 팬케어 프로젝트: 프리랜서 분석가, 엔지니어와 함께?
- FCM(CRM과 유사. Fan Care Management)
- 셀럽 입장에서는 팬 관리가 일
- 팬의 리텐션 유지, 셀럽의 리텐션 유지 중 후자(팬에게 잘 해주는 것)가 중요하다고 판단
- 이슈: 셀럽이 어떻게 더 적극적으로 팬심을 쓰게 할 수 있을까? 이탈 예측 및 방지는 어떻게?
- 팬케어 보고서(팬 회원분석 리포트) 메일링 서비스. “열심히 하니 팬이 잘 해주는구나” 느껴서, 계속해서 서비스 쓰도록 유도
- 찐팬, 예비 찐팬, 잠든팬 군집화. 군집화 알고리즘 특성상 수치가 꼭 같아야 같이 묶기 때문에, 임의로 특정 수치도 참고함. 셀럽에게 보여주는 군집이기 때문에 오분류시 문제가 생길 수 있음
- 팬심 M 이탈 예측 모델
- 셀럽의 수익모델: 후원 수수료. 그래서 셀럽의 리텐션 유지가 중요
- 이탈 가능성이 높은 셀럽 사전 예측
- 셀텁의 리텐션은 팬의 리텐션에 직접적인 영향. 이걸 수치로 확인할 수 있다면, 운영팀의 원활한 모니터링에 도움 줌
- 모델 구성 요소
- 이탈 정의: 셀럽들의 활동 주기 탐색. 결국 셀럽별로 다르기 때문에, 7일 기준/14일 기준/… 등 여러개 만듦
- 모델 학습시킬 속성들: 로그 데이터이기 때문에 모든 페이지 방문 로그도 변수로 때려박다가, 추후 이탈에 영향 주는 속성만 남김
- 어떤 모델? (성능 위주, 해석 위주 모델 등). 그리고 채팅방별로 각각 다른 팬 특성을 어떻게 학습할 것인가?
- 모델링에 tabnet 사용(DT - DNN 장점만 사용. 가볍고 정교한 딥러닝 모델). 자동 재학습은 Airflow 및 GCP VM(서버에 올려 스케줄링)
- Airflow 구성
- Master node 1개 (램 16g, 스토리지 50g): Airflow 서버 구동
- Worker node 2개 (4g, 10g): Airflow DAG에 작성된 파이썬 스크립트 작동. 변수 기여도와 현재 트렌드, KPI 함께 볼 수 있는 대시보드 제공
- 팬심은 마케터가 없음. 광고를 하지 않아도 계속 사용자가 유입됨. 데이터 이용하여 본질적인 서비스에 집중하기 때문인 듯
5. 내 집 마련을 위한 생성형 AI (부동이 GPT)
- openAI를 활용한 프롬프트 엔지니어링?
- 기존 부동산 플랫폼은 ‘금천구에 주변에 걷기 좋은 공원 있는 아파트’ 같이 정성적 질문에 답변 불가
- 부동산 청약 아파트 비즈니스에 특화된 생성형 AI 개발
- PaaS: 도메인 특화 데이터로 커스터마이징 가능? SaaS: openAI chatgpt 사용
- 데이터 수집: 청약홈
- 서울, 경기, 인천 최근 3년간 청약, 2020~2027 입주 예정 548개 아파트 데이터 수집
- Azure 통해 개발환경 구축
- 프롬프트 엔지니어링
- LLM은 In-contect Learning. 맥락 통해 사용자 요구에 맞춤
- 제로샷 러닝 → 원샷 러닝 → 퓨샷 러닝 (학습할 사례 점차 추가)
- AzureGPT의 특징: 검색기반 gpt. 원래 데이터를 교체하여 검색 성능 향상
- 다만 검색에 용이하게 pdf 파일을 만들어야 함 (학습하기 위한 데이터). 아파트에 관련한 정보 작성
- 아파트 이름에 대해 자주 작성(단락마다)
- 고유명사에 대해 한국어/영어 상호 번역할 수 있도록 함
- 프롬프트 엔지니어링 원칙
- 구체적이고 명확한 목적이 있는 프롬프트 작성 (질문이 길더라도 원하는 정보를 모두 작성)
- 광명시 아파트 중에서 7호선 역세권 아파트 알려줘 vs 지하철 7호선을 이용해야 통근이 편리한데, 광명시 아파트 중에서 7호선 역세권 아파트 알려줘 중 후자. 이렇게 해야 도보로 가기 편한 아파트를 걸어줌
- 한국어보다는 영어로 질문
- 문맥. 일관된 주제에 대해 피드백을 주고받으며 대화. 다른 문맥에 대해서는 새 창을 여는 것이 좋음
- 순서. 질문 처리 과정을 명시하고, 포괄적인 질문 → 구체적인 질문으로 범위를 좁혀감
- ex: 국민평형(84m^2) 관련 정보 얻고자 할 때
- 국민평형이 자주 사용되는 용어인가요? → A아파트도 국민평형을 공급하나요? → A 아파트가 공급하는 국민평형의 타입에 관한 정보 알려줘
- 근데 퓨삿 러닝을 시켜 이렇게 대화하다 보면, 또다른 아파트에 대해서는 국민평형에 대한 잘못된 정보를 제공하기도 함
- 그래서 국민평형은 모든 아파트에 공통 적용된다는 정보 추가로 학습시킴
- 근데 이런 식으로 너무 자세하게 프롬프트를 작성해야 한다는 단점이 있음
- 역할. 가상의 상황 설정하고, 부동이와 내가 맡을 역할 분담
- 구체적이고 명확한 목적이 있는 프롬프트 작성 (질문이 길더라도 원하는 정보를 모두 작성)
6. 혼란한 세상에서 만든 나만의 성장 방정식
- 성장을 위한 Action Item들 소개
- 지금이 LLM의 등장으로 데이터에서 가장 혼란한 시기라고 함. 어떤 공부를 해야 할까?
- 새로운 현상이 나와서 혼란한 것. 근데 이 업계는 매년 새로운 발견들이 있었음. chatgpt가 임팩트가 클 뿐
- 공부하는 것 결정 기준: 바로 사용하지 않을 것을 공부하는 것은 효율 좋지 않음
- 업무 효율을 위해, 30분 단위로 작업환경+업무+시간? 기록
- 개인적으로 감명받았던 점
- 내가 어떤 환경일 때 집중력이 높은가? 그런 상황을 의도적으로 만들 수 있는가? 오전/오후 등 어느 시간이 집중력이 좋은가?
- ‘함께 자라기’ 책. 불확실한 상황에서 어떻게 접근할지 다룸
- 업무에 따라 2차원 매트릭스로 분류(실력과 작업 난이도). 두려움/몰입/지루함 3가지 종류 있음
- 여전히 공부할 것은 많지만, 시간이 없을 때
- 잘하는 사람에게 배움. 어떤 업무에 대해 좋았던 자료 추천받거나, 시행착오를 물어봄
- 그 사람의 모습 기록 (일 잘하는 사람의 오답노트)
- 데이터 조직이 커지며 다른 조직과 협업 시작. 다른 팀과의 신뢰 관계가 중요
- 우리 근처에 있는 팀의 현재 문제를 해결해 주는가? 해결해 주면서 신뢰감 형성, 장기적인 협력 관계
- 프로세스를 만들기 위한 고민도 함. 프로세스 이코노미 책
- RIZE(SaaS): 하루동안 활동 자동 트랙킹
- 근데 회사에서는 보안상 쓸 수는 없을듯. 아이패드 가져가면 가능하려나?
- 프로젝트 리팩토링
- 과거에 했던 프로젝트를 다시 한다면, 어떻게 만들 것인가? 툴은 뭘로?
- 주커버그: 위대한 회사가 되려면 필요한 것: 끝없는 실행, 효율성, 엄격함, 더 나아지려는 태도
7. 뭐? 모델링을 안해도 된다구? Data-Centric AI
- 업스테이지 데이터 사이언티스트
- 참고할 글: Data-Centric AI와 Real-World — Upstage (업스테이지 블로그)
- 일반적인 AI = code(모델/알고리즘) + data. 데이터가 있는 코드
- AI 연구는 대부분 model-centric. 모델을 정해 두고 그 안에서 최고의 성능을 찾음
- LLM을 이용하여, 이제는 모델을 만들려면 간단한 프롬프팅으로 가능
- Data-Centric AI for 정형 데이터
- Data Flywheel: 데이터가 바뀌면서 모델도 바뀌는 경우
- OCR의 경우, 오늘-내일의 모델이 크게 다르지 않음
- 이커머스의 경우, 계속해서 새로운 상품과 유저가 생기며 트렌드 변화. 모델이 계속해서 변화해야 함
- ROI: 한계효용의 체감
- Andrew Ng의 결과. Model-centric의 경우 성능 변화가 거의 없음. Data-Centric은 눈에 띄는 향상을 보임(비정형 데이터 결과). 근데 정형도 이런 향상이 있음
- Data Flywheel: 데이터가 바뀌면서 모델도 바뀌는 경우
- AI = code & data
- HuggingFace 보면, 모델 아키텍처들은 다 비슷함. 이제는 Data-Centric AI로 갈 필요가 있음
- LLMops
- 기존 서비스들의 SLA(서비스 지연 ms 단위)와는 다르게, 초 단위의 지연. 그마저도 안정적이지 않음
- 아직 실 서비스에서는 정착되지 않음. Small LLA 등을 쓰는 식으로 해결 중
후기
올해 공부나 프로젝트에 굉장히 소홀한 상태였는데, 자극제가 되는 시간이었다. 데이터야놀자 후기 글도 당일날 메모해 놓고, 두 달이 지나서야 블로그 글을 썼다. 행사 당일만 자극됐지, 막상 두 달 간은 다시 일상으로 돌아갔다.
프로젝트 마무리를 맹그로브 고성에서 워케이션으로 할 계획이다. 변성윤님의 데이터야놀자 강의도 그렇고, 워케이션 글이 자극이 되었다. 내년 1월 말에 가려고 하는데, 그 때까지 프로젝트 과제들을 어느 정도 해 놓고, 워케이션 가서 집중적으로 마무리 하려고 한다. 입사 후에 이런저런 핑계로 운동 외에 별로 이룬 것이 없었는데, 이번 기회에 반드시 프로젝트를 끝내야겠다. 공부하는 습관도 다시 찾기를 바란다.
- 참고 링크