
카카오톡 챗봇에서 크고 작은 개선 사항들을 정리해 보았다. 지속적으로 업데이트할 예정이다.
1. 아티스트 이름 번역
Spotify에서 한국 아티스트는 한국어로 검색해도 나오지만, 외국 아티스트는 한국어로 검색했을 때 나오지 않는 경우가 있다. (2020/07/03 기준)
eminem: 검색됨에미넴: 검색되지 않음
또한 띄어쓰기를 제대로 하지 않으면 나오지 않는 경우도 있다.
레이디 가가: 검색됨레이디가가: 검색되지 않음
이는 사용자 입장에서 매우 불편한 부분이다. 그래서 구글 번역기를 통해 한국어 검색어를 영어로 변환 한 뒤 사용하기로 했다. googletrans라는 라이브러리를 이용하면 된다. Google 번역기와 같은 서버를 사용한다. pip install googletrans==4.0.0rc1 (버전 주의)로 설치 후 사용하면 된다.
from googletrans import Translator
translator = Translator()
print(translator.translate('콜드플레이', dest="en").text)
# Cold play
print(translator.translate('퀸', dest="en").text)
# queen
print(translator.translate('트래비스', dest="en").text)
# Travis
print(translator.translate('포스트말론', dest="en").text)
# Post Malone
하루에 사용할 수 있는 횟수가 정해져 있지만, Google Cloud Translation을 사용하는 것보다 간편하다. 트래픽 이슈가 생길 경우 이 방법을 고려해 볼 것이다.
2. 예외 아티스트
자전거 탄 풍경이라는 가수를 모두 알 것이다. 너에게 난~ 해질녘 노을처럼~~ 카카오톡 챗봇 만들기 1에서 카카오톡 챗봇의 엔티티에 대해 언급했는데, 자전거 탄 풍경은 @sys.person.group 엔티티를 통해 파라미터 매핑이 되지만 자전거는 단어가 너무 포괄적이라 그런지 매핑되지 않는다.

참고로 이 메시지는 스킬(Lambda에서 수신)을 통해 처리하는 것이 아니다. 오픈빌더에서 시나리오의 왼쪽 메뉴를 보면 폴백 플록이라는 게 있다. 봇이 사용자의 말을 알아듣지 못하고, 이해할 수 없을 때 내뱉는 메시지이다. 폴백 블록으로 들어가 봇 응답을 아래와 같이 설정한 것이다.
다시 본론으로 돌아가자. 이 챗봇은 아티스트 이름을 입력받아 처리하는 것이다. 자전거를 입력하면 일단 Search API를 통해 검색이 되도록 하려고 한다.
해결 방법은 간단하다. 시나리오에서 사용자 발화 예시로 자전거를 넣어주고 더블클릭하여 @sys.person.group 엔티티를 수동으로 매핑시킨다. 그리고 저장하면 끝이다.
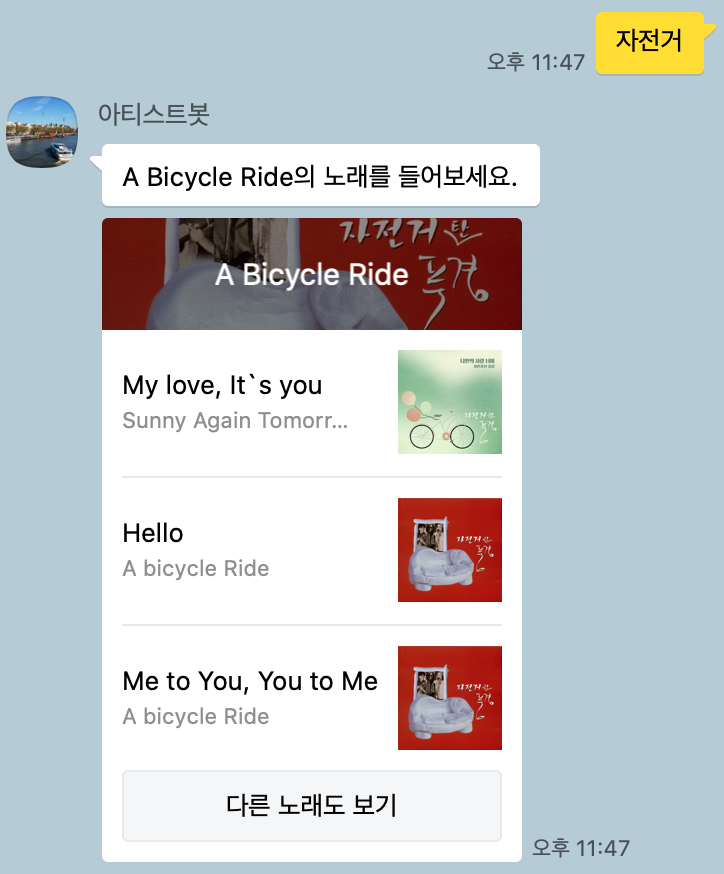
이제 자전거의 검색 결과로 자전거 탄 풍경이 나오게 된다. 여기에 표시되지는 않지만, request를 확인해 보면 group 파라미터도 정상적으로 생긴다.
3. 비동기/동기 invoke lambda 사용
카카오톡 챗봇 만들기 2에서 새로운 아티스트가 추가되었을 때 MySQL에 아티스트 데이터를, DynamoDB에 top_tracks 데이터를 저장했다. 이전의 메시지 요청을 통해 아티스트가 이미 DB에 저장되어 있었으면 문제가 없는데, 해당 요청을 통해 새로 추가된 아티스트의 경우 아래와 같이 top_tracks 데이터가 리턴되지 않는 오류가 발생했다.
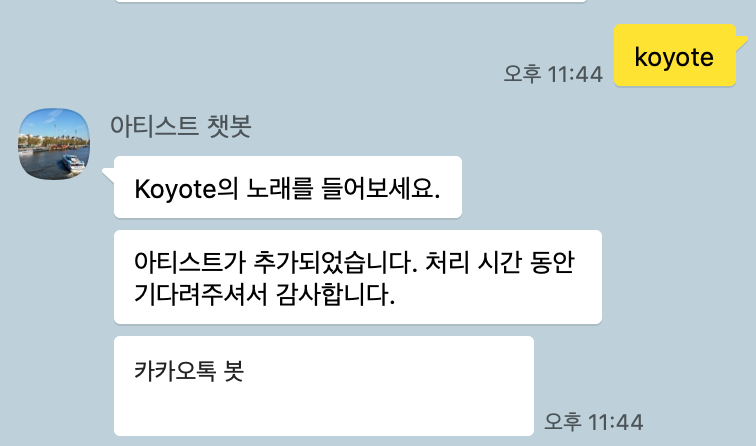
DynamoDB에 데이터를 저장하기 위해, Lambda function에서 다른 Lambda function을 사용하는 invoke 방식을 사용했다. 여기서 궁금증이 생겼다.
invoke lambda가 비동기 방식으로 이루어져서, DynamoDB에 데이터 저장이 완료되기 전에 데이터를 불러오느라 위와 같이 데이터가 없는 현상이 발생한 것인가??
동기 방식과 비동기 방식의 차이를 간략히 설명하면 다음과 같다.
- 동기(Synchronous) 방식: 함수를 실행하고 응답을 기다림. 이벤트 실행이 종료되면 응답이 반환되고, 다음 이벤트를 실행할 수 있음

- 비동기(Asynchronous) 방식: 함수의 응답을 기다리지 않고 다음 이벤트를 처리함. 대기열에 여러 Event를 넣어 병렬적으로, 동시다발적으로 처리 가능

이 문제가 발생하고, 새로 추가된 아티스트는 DB 데이터가 아닌 API 결과 를 메시지에 넣어 주는 것으로 해결했다. 하지만 invoke lambda를 동기/비동기 방식으로 구분하여 사용하는 방법이 궁금해졌다.
현재 invoke lambda를 실행하는 코드는 다음과 같다.
import boto3
def invoke_lambda(fxn_name, payload, invocation_type = 'Event'):
lambda_client = boto3.client('lambda')
invoke_response = lambda_client.invoke(
FunctionName = fxn_name,
InvocationType = invocation_type,
Payload = json.dumps(payload)
)
return invoke_response
위와 같이 InvocationType을 Event로 해 줄 경우 Lambda 함수를 비동기식으로 호출한다. InvocationType을 따로 지정해 주지 않으면 동기식으로 호출한다.
4. Top Tracks 업데이트
현재 Top Tracks 데이터를 챗봇에서 보여주는 과정은 다음과 같다.
- 이미 있는 아티스트:
DynamoDB에서 가져옴 - 메시지 입력시 새로 추가되는 아티스트:
Spotify API에서 가져옴
한 번 저장된 아티스트의 데이터가 업데이트되지 않는 구조이다.
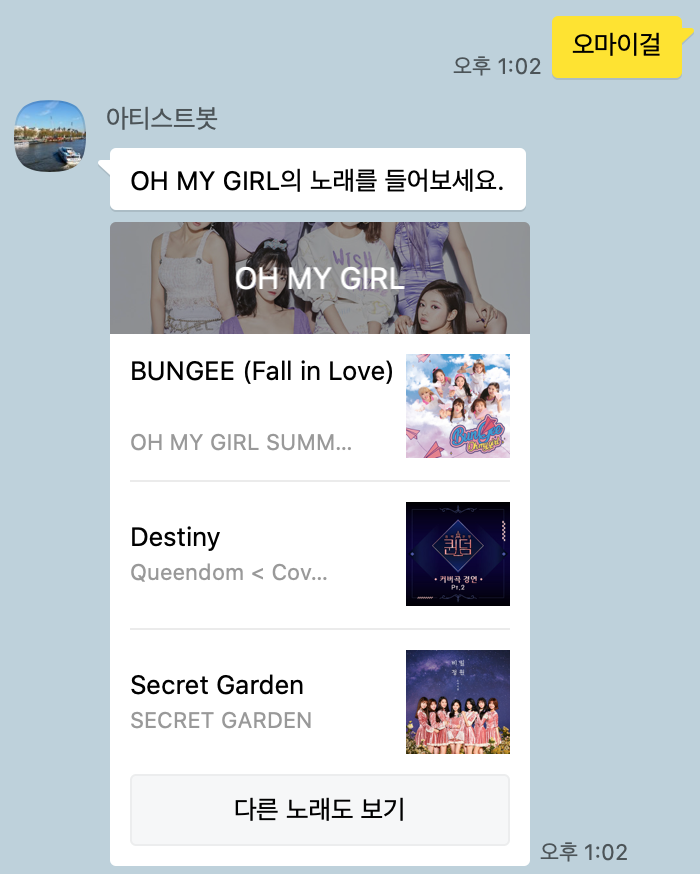
오마이걸의 경우 몇 달 전에 컴백하여 살짝 설렜어 (Nonstop), Dolphin 등의 노래를 발표했고, 현재 (2020/07/13) 이 두 곡이 Top Track API 결과상에서 상위 2개를 차지한다. 따라서 챗봇에서 오마이걸로 검색하면 이 두 곡이 나와야 하는데, 컴백 전에 데이터가 이미 생성되어 아직도 아래와 같이 나온다.
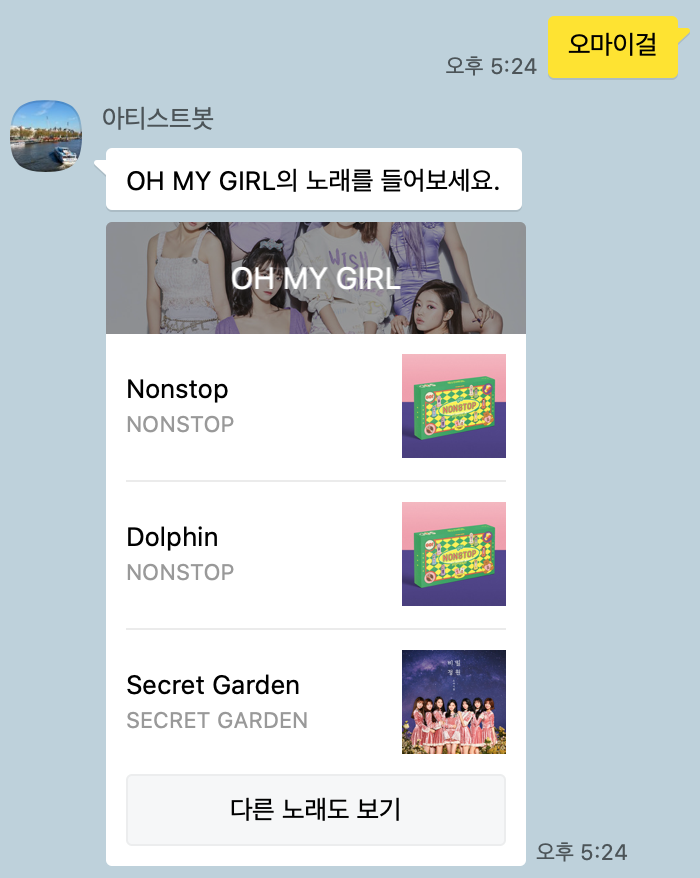
이 문제를 해결하기 위해 매일 Top Tracks 데이터를 S3 및 DynamoDB에 자동적으로 업데이트하여, 당일 기준 데이터를 제공하도록 했다. 아래와 같이 Nonstop, Dolphin을 확인할 수 있다.
- 데이터 업데이트 자동화에 대해서는 Amazon EC2와 리눅스 crontab을 이용한 배치 처리에 서술해 놓았다.