
카카오톡 챗봇 개발기를 아래와 같이 시리즈로 포스팅하고 있다.
- 기본적인 환경설정 및 메시지 응답 테스트
- 입력한 아티스트의 정보 제공
- 관련 아티스트 및 노래 추천
지난 글에서 AWS Lambda를 이용한 카카오톡 챗봇 세팅에 대해 다루었다. 이번 글에서는 Spotify API 데이터를 이용하여, 아티스트를 요청받으면 해당 아티스트에 대한 정보를 response로 주는 것에 대해 다룰 것이다.
목차는 다음과 같다. 스압 주의
중간 중간에 코드를 첨부했는데, 전체 코드는 Github에 올려 놓았다.
카카오톡 말풍선 종류
카카오톡 챗봇으로 용도와 목적에 따라 여러 종류의 메시지를 보낼 수 있다. 여기서는 내가 사용할 세 가지만 간단히 소개하겠다.
1. SimpleText
단순한 텍스트 출력이다.

지난 글에서 테스트해 본 메시지 종류이다. Lambda 코드에서 아래 형태의 json 변수를 반환해야 한다.
{
"version": "2.0",
"template": {
"outputs": [
{
"simpleText": {
"text": "간단한 텍스트 요소입니다."
}
}
]
}
}
2. BasicCard
이미지와 설명, 버튼이 함께 있는 카드 형태의 메시지이다.

json 형태는 다음과 같다.
{
"version": "2.0",
"template": {
"outputs": [
{
"basicCard": {
"title": "보물상자",
"description": "보물상자 안에는 뭐가 있을까",
"thumbnail": {
"imageUrl": "http://k.kakaocdn.net/dn/83BvP/bl20duRC1Q1/lj3JUcmrzC53YIjNDkqbWK/i_6piz1p.jpg"
},
"profile": {
"imageUrl": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT4BJ9LU4Ikr_EvZLmijfcjzQKMRCJ2bO3A8SVKNuQ78zu2KOqM",
"nickname": "보물상자"
},
"social": {
"like": 1238,
"comment": 8,
"share": 780
},
"buttons": [
{
"action": "message",
"label": "열어보기",
"messageText": "짜잔! 우리가 찾던 보물입니다"
},
{
"action": "webLink",
"label": "구경하기",
"webLinkUrl": "https://e.kakao.com/t/hello-ryan"
}
]
}
}
]
}
}
thumbnail > imageUrl이 보이는 이미지의 주소이다. profile > imageUrl은 프로필 이미지인데 카드에 노출되는 부분은 아닌 것 같다. social도 마찬가지이다. 그래서 나는 title, description, thumbnail, buttons 부분만 담았다. 버튼의 경우 messageText는 누르면 해당 메시지가 입력되며, webLinkUrl은 누르면 해당 링크로 연결된다.
3. ListCard
여러 줄로 구성된 리스트형 메시지이다. 글 작성 당시에는 제목에 이미지를 넣을 수 있었으나, 카카오톡 측에서 업데이트로 인해 2020년 10월 27일 현재 제목에는 이미지를 넣을 수 없다.

json 형태는 다음과 같다.
{
"version": "2.0",
"template": {
"outputs": [
{
"listCard": {
"header": {
"title": "카카오 i 디벨로퍼스를 소개합니다"
},
"items": [
{
"title": "Kakao i Developers",
"description": "새로운 AI의 내일과 일상의 변화",
"imageUrl": "http://k.kakaocdn.net/dn/APR96/btqqH7zLanY/kD5mIPX7TdD2NAxgP29cC0/1x1.jpg",
"link": {
"web": "https://namu.wiki/w/%EB%9D%BC%EC%9D%B4%EC%96%B8(%EC%B9%B4%EC%B9%B4%EC%98%A4%ED%94%84%EB%A0%8C%EC%A6%88)"
}
},
{
"title": "Kakao i Open Builder",
"description": "카카오톡 채널 챗봇 만들기",
"imageUrl": "http://k.kakaocdn.net/dn/N4Epz/btqqHCfF5II/a3kMRckYml1NLPEo7nqTmK/1x1.jpg",
"link": {
"web": "https://namu.wiki/w/%EB%AC%B4%EC%A7%80(%EC%B9%B4%EC%B9%B4%EC%98%A4%ED%94%84%EB%A0%8C%EC%A6%88)"
}
},
{
"title": "Kakao i Voice Service",
"description": "보이스봇 / KVS 제휴 신청하기",
"imageUrl": "http://k.kakaocdn.net/dn/bE8AKO/btqqFHI6vDQ/mWZGNbLIOlTv3oVF1gzXKK/1x1.jpg",
"link": {
"web": "https://namu.wiki/w/%EC%96%B4%ED%94%BC%EC%B9%98"
}
}
],
"buttons": [
{
"label": "구경가기",
"action": "webLink",
"webLinkUrl": "https://namu.wiki/w/%EC%B9%B4%EC%B9%B4%EC%98%A4%ED%94%84%EB%A0%8C%EC%A6%88"
}
]
}
}
]
}
}
나는 안내 메시지는 SimpleText 형태로, 아티스트에 관한 정보는 아티스트 이미지와 함께 BasicCard 형태로, 아티스트의 인기 트랙은 ListCard 형태로 전달하기로 하여 이 세 개를 소개해 보았다. 이외 여러 형태의 메시지에 대해서는 공식 문서에 나와 있다.
Spotify 가입 및 권한 설정
Spotify API를 사용하기 위해서는 서비스에 우선 가입해야 한다. 한국에서는 서비스되지 않기 때문에 VPN을 통해 우회해야 한다. 우회 방법에 대해서는 한국에서 Spotify(스포티파이) 사용하기에 나와 있다. TunnelBear라는 앱을 사용하면 된다. TunnelBear는 월 500MB만 무료로 제공하고 있는데, 가입 시에만 VPN을 사용하고 이후 로그인 정보가 남아 있는 세션에서는 다시 VPN을 사용할 필요가 없기 때문에 신경 쓰지 않아도 된다.
- 예전에 이와 관련해서 문서를 찾아보았을 때 VPN의 위치와 계정 상에서 위치를 같게 할 필요가 있던 것으로 기억한다. 나는 TunnelBear 위치와 계정 상의 위치를 미국으로 설정했다.
Spotify에 가입했으면, Dashboard로 들어가 앱을 생성해야 한다. 생성 후 앱으로 들어가면 아래와 같은 창에서 Client ID, Client Secret이 보일 것이다. 이 정보가 API 데이터에 접근할 때 사용해야 할 인증 정보이다.

API 이용시 Authorization에 관해서는 크게 두 가지가 있다.
- App Authorization: 앱을 통해 API에 접근하는 것이다. 서비스를 이용하는 사용자의 정보가 따로 필요하지 않다.
- User Authorization (OAuth): 서비스를 이용하는 사용자 정보를 통해 API에 접근하는 것이다. 예를 들어 왓챠 같은 앱을 사용하려면 따로 가입할 필요 없이 Google로 로그인 할 수도 있는데, 이 때 이 방식을 사용한다. Google 계정 정보 를 가지고 왓챠 서비스를 이용하는 것이다.
내가 개발하려는 카카오톡 챗봇에서는 사용자의 Spotify 계정 정보 없이 아티스트에 대한 서비스를 제공할 것이다. 따라서 App Authorization 방식을 사용했다. 이 방식은 다음 이미지의 순서대로 작동한다.

- 카카오톡 사용자가 메시지를 요청하면 Spotify 앱 작동이 시작된다. 이 때 위에서 언급한 Spotify 계정 정보인
cliend_id,cliend_secret, 그리고grant_type이 필요하다. grant_type은client_credentials로 설정하면 된다. - 그러면 Spotify에서 사용자에게
access_token을 부여한다. 이 토큰을 가지고 API 데이터를 쿼리하면 된다.
이 과정을 위한 코드는 다음과 같다.
# header 발급 위한 함수
import base64
def get_headers(client_id, client_secret):
endpoint = "https://accounts.spotify.com/api/token"
# cliend_id, client_secret은 Base 64 encoded string이어야 함
encoded = base64.b64encode("{}:{}".format(client_id, client_secret).encode('utf-8')).decode('ascii')
headers = {
"Authorization": "Basic {}".format(encoded)
}
payload = {
"grant_type": "client_credentials" # grant_type은 고정
}
r = requests.post(endpoint, data=payload, headers=headers)
access_token = json.loads(r.text)['access_token']
headers = {
"Authorization": "Bearer {}".format(access_token)
}
return headers
Spotify 데이터 저장
이제 데이터를 가져올 수 있다. Web API Reference에서 아티스트, 앨범, 검색 결과, 트랙 등 여러 종류의 데이터에 대해 나와 있다. 이번 글에서는 다음 두 가지를 사용할 것이다. 코드를 작성하지 않아도, Spotify 로그인 후 각 링크에서 쿼리 결과를 테스트해 볼 수 있다.
- Search: 검색어를 입력 결과로 나오는 아티스트 정보 (아티스트 ID 포함)
- Top Tracks: 아티스트 ID를 입력하면 나오는 아티스트의 인기 트랙
1. Search
queen으로 검색해 보았다.
import requests
def search_artist(artist_name):
headers = get_headers(client_id, client_secret)
## Spotify Search API
params = {
"q": artist_name,
"type": "artist",
"limit": "1" # 가장 상위 결과만
}
r = requests.get("https://api.spotify.com/v1/search", params=params, headers=headers)
raw = json.loads(r.text)
return raw
search_artist('queen')
- params에서
q는 검색어이다. type은 album, artist, playlist, track, show, episode 등을 정할 수 있는데, 나는 아티스트가 필요하므로artist로 설정했다.limit은 검색 결과 개수를 정하는 부분이며, 가장 상위 검색어로 나온 결과를 사용할 것이므로 1로 설정했다.
결과는 다음과 같다.
{
"artists": {
"href": "https://api.spotify.com/v1/search?query=queen&type=artist&offset=0&limit=1",
"items": [
{
"external_urls": {
"spotify": "https://open.spotify.com/artist/1dfeR4HaWDbWqFHLkxsg1d"
},
"followers": {
"href": null,
"total": 26100989
},
"genres": [
"glam rock",
"rock"
],
"href": "https://api.spotify.com/v1/artists/1dfeR4HaWDbWqFHLkxsg1d",
"id": "1dfeR4HaWDbWqFHLkxsg1d",
"images": [
{
"height": 806,
"url": "https://i.scdn.co/image/b040846ceba13c3e9c125d68389491094e7f2982",
"width": 999
},
{
"height": 516,
"url": "https://i.scdn.co/image/af2b8e57f6d7b5d43a616bd1e27ba552cd8bfd42",
"width": 640
},
{
"height": 161,
"url": "https://i.scdn.co/image/c06971e9ff81696699b829484e3be165f4e64368",
"width": 200
},
{
"height": 52,
"url": "https://i.scdn.co/image/6dd0ffd270903d1884edf9058c49f58b03db893d",
"width": 64
}
],
"name": "Queen",
"popularity": 90,
"type": "artist",
"uri": "spotify:artist:1dfeR4HaWDbWqFHLkxsg1d"
}
],
"limit": 1,
"next": "https://api.spotify.com/v1/search?query=queen&type=artist&offset=1&limit=1",
"offset": 0,
"previous": null,
"total": 3174
}
}
artists > items[0]에 원하는 아티스트의 정보가 담겨져 있다. 이 정보를 MySQL에 저장할 것인데, 이 때 genres는 위에서 볼 수 있듯이 - [“glam rock”, “rock”] - 한 아티스트에 여러 개의 값이 있는 경우가 많다. 장르가 없는 경우도 있다.
아티스트 테이블을 구성할 때 장르 때문에 행이 많아지면 구조가 복잡해지므로, 아래와 같이 두 개의 테이블로 나눌 것이다. artists 테이블의 id와 artist_genres 테이블의 artist_id가 join되는 구조이다.
- artists
| 칼럼 | 결과에서의 위치 | 설명 | 데이터 타입 |
|---|---|---|---|
id |
id | 아티스트 ID | varchar(255) |
name |
name | 아티스트 이름 | varchar(255) |
followers |
followers > total | 팔로워 수 | int(11) |
popularity |
popularity | 인기도 | int(11) |
url |
external_urls > spotify | Spotify에서 해당 아티스트에 대해 정리된 링크 주소 | varchar(255) |
image_url |
images[0] > url | 아티스트 썸네일 이미지 주소 (여러 이미지가 나오는데, 첫 번째 결과를 사용할 것) | varchar(255) |
- artist_genres
| 칼럼 | 결과에서의 위치 | 설명 | 데이터 타입 |
|---|---|---|---|
artist_id |
id | 아티스트 ID | varchar(255) |
genre |
genres | 각 장르 | varchar(255) |
updated_at |
자동 삽입 | 테이블에 추가된 날짜와 시각 | timestamp |
artist_genres 테이블은 아래와 같이 한 아티스트에 장르 개수만큼의 행 개수를 가지는 구조이다.

- 물론
NoSQL을 사용해서json결과를 그대로 저장해도 되지만, 학습을 위해 여러 종류의 DB를 사용해 보고 있다. 아래에 나올 Top Tracks 데이터는 AWS에서 제공하는 NoSQL인DynamoDB를 사용할 것이다. - 참고로 실제 Spotify 서비스에서 검색 결과가 어떻게 나오는지 보고 싶다면, open.spotify.com에서 확인해 볼 수 있다(이것도 Spotify 로그인이 필요하다). 한국 아티스트의 경우 한글로도 검색이 가능하며, 검색어에 따라서 아티스트가 아예 나오지 않을 수도 있다.
- 분량상 MySQL에 데이터를 삽입하는 과정은 생략하겠다.
2. Top Tracks
Top Tracks에서는 아티스트의 이름을 파라미터로 하여 해당 아티스트의 인기 트랙을 얻을 수 있다. 다만 Search에서는 검색어를 Query Parameter 로 사용했는데, Top Tracks에서는 아티스트의 ID가 API 엔드포인트 중 일부로 들어가는 Path Parameter 형태로 사용해야 한다. Query Parameter 로는 country가 들어간다. 해당 국가에서의 인기 트랙이 나오게 된다.
Queen의 미국에서의 top tracks을 보려면, 아래와 같이 쿼리해야 한다.
def top_tracks(artist_id):
headers = get_headers(client_id, client_secret)
# Path Parameter: API 엔드포인트에 들어감 - {} 부분
URL = "https://api.spotify.com/v1/artists/{}/top-tracks".format(artist_id)
# Query Parameter
params = {
'country': 'US'
}
r = requests.get(URL, params=params, headers=headers)
raw = json.loads(r.text)
return raw
top_tracks('1dfeR4HaWDbWqFHLkxsg1d') # Queen의 id
결과는 다음과 같다. 여러 트랙이 나오는데, 분량상 한 트랙의 결과만 가져왔다.
{
"tracks": [
{
"album": {
"album_type": "album",
"artists": [
{
"external_urls": {
"spotify": "https://open.spotify.com/artist/1dfeR4HaWDbWqFHLkxsg1d"
},
"href": "https://api.spotify.com/v1/artists/1dfeR4HaWDbWqFHLkxsg1d",
"id": "1dfeR4HaWDbWqFHLkxsg1d",
"name": "Queen",
"type": "artist",
"uri": "spotify:artist:1dfeR4HaWDbWqFHLkxsg1d"
}
],
"external_urls": {
"spotify": "https://open.spotify.com/album/6X9k3hSsvQck2OfKYdBbXr"
},
"href": "https://api.spotify.com/v1/albums/6X9k3hSsvQck2OfKYdBbXr",
"id": "6X9k3hSsvQck2OfKYdBbXr",
"images": [
{
"height": 640,
"url": "https://i.scdn.co/image/ab67616d0000b273ce4f1737bc8a646c8c4bd25a",
"width": 640
},
{
"height": 300,
"url": "https://i.scdn.co/image/ab67616d00001e02ce4f1737bc8a646c8c4bd25a",
"width": 300
},
{
"height": 64,
"url": "https://i.scdn.co/image/ab67616d00004851ce4f1737bc8a646c8c4bd25a",
"width": 64
}
],
"name": "A Night At The Opera (Deluxe Remastered Version)",
"release_date": "1975-11-21",
"release_date_precision": "day",
"total_tracks": 18,
"type": "album",
"uri": "spotify:album:6X9k3hSsvQck2OfKYdBbXr"
},
"artists": [
{
"external_urls": {
"spotify": "https://open.spotify.com/artist/1dfeR4HaWDbWqFHLkxsg1d"
},
"href": "https://api.spotify.com/v1/artists/1dfeR4HaWDbWqFHLkxsg1d",
"id": "1dfeR4HaWDbWqFHLkxsg1d",
"name": "Queen",
"type": "artist",
"uri": "spotify:artist:1dfeR4HaWDbWqFHLkxsg1d"
}
],
"disc_number": 1,
"duration_ms": 354320,
"explicit": false,
"external_ids": {
"isrc": "GBUM71029604"
},
"external_urls": {
"spotify": "https://open.spotify.com/track/7tFiyTwD0nx5a1eklYtX2J"
},
"href": "https://api.spotify.com/v1/tracks/7tFiyTwD0nx5a1eklYtX2J",
"id": "7tFiyTwD0nx5a1eklYtX2J",
"is_local": false,
"is_playable": true,
"name": "Bohemian Rhapsody - 2011 Mix",
"popularity": 75,
"preview_url": null,
"track_number": 11,
"type": "track",
"uri": "spotify:track:7tFiyTwD0nx5a1eklYtX2J"
},
...
]
}
tracks 안에 album으로 시작하는 여러 트랙들이 담기게 된다. 이 데이터를 AWS에서 제공하는 NoSQL인 DynamoDB에 저장하는데, 이 작업을 위해서는 Lambda 함수에서 또 다른 Lambda 함수를 호출할 것이다. 이 작업을 invoke라고 한다.
invoke를 하기 위해서는 다른 Lambda함수를 invoke하기 위한 권한이 필요하다. AWS IAM에서 원래 Lambda 함수에 AWSLambdaFullAccess 권한을 부여해야 한다.
먼저 Lambda 함수 페이지로 들어가 권한 탭에 있는 역할 이름 을 클릭한다.
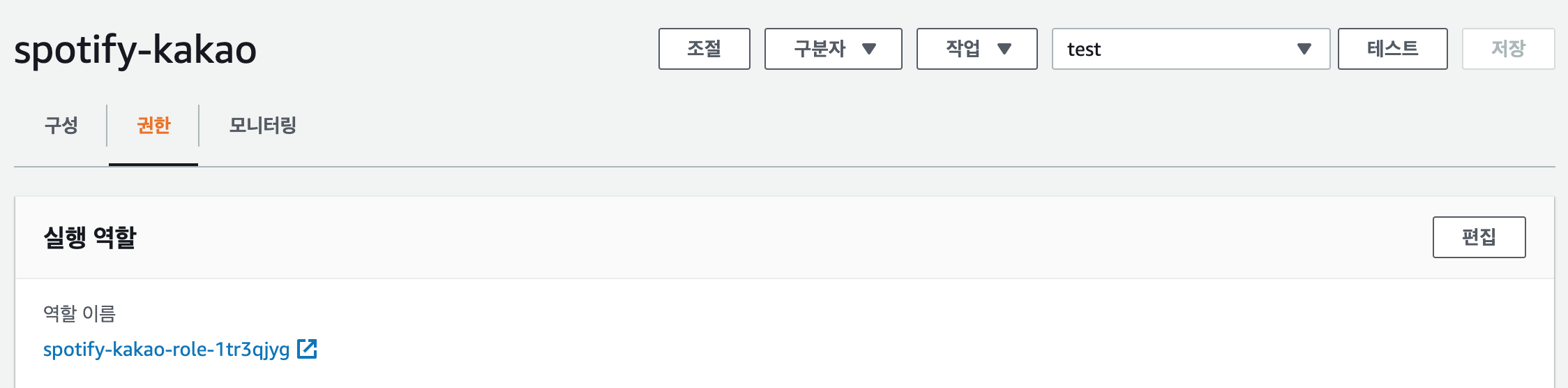
IAM으로 들어가게 되면, 권한 탭에 현재 이 역할에서 사용 가능한 정책들이 나와 있다. 정책 연결 로 들어간다.

AWSLambdaFullAccess를 입력하고 체크 후 정책 연결 버튼을 클릭하여 완료한다. 모두 입력하지 않아도 된다.
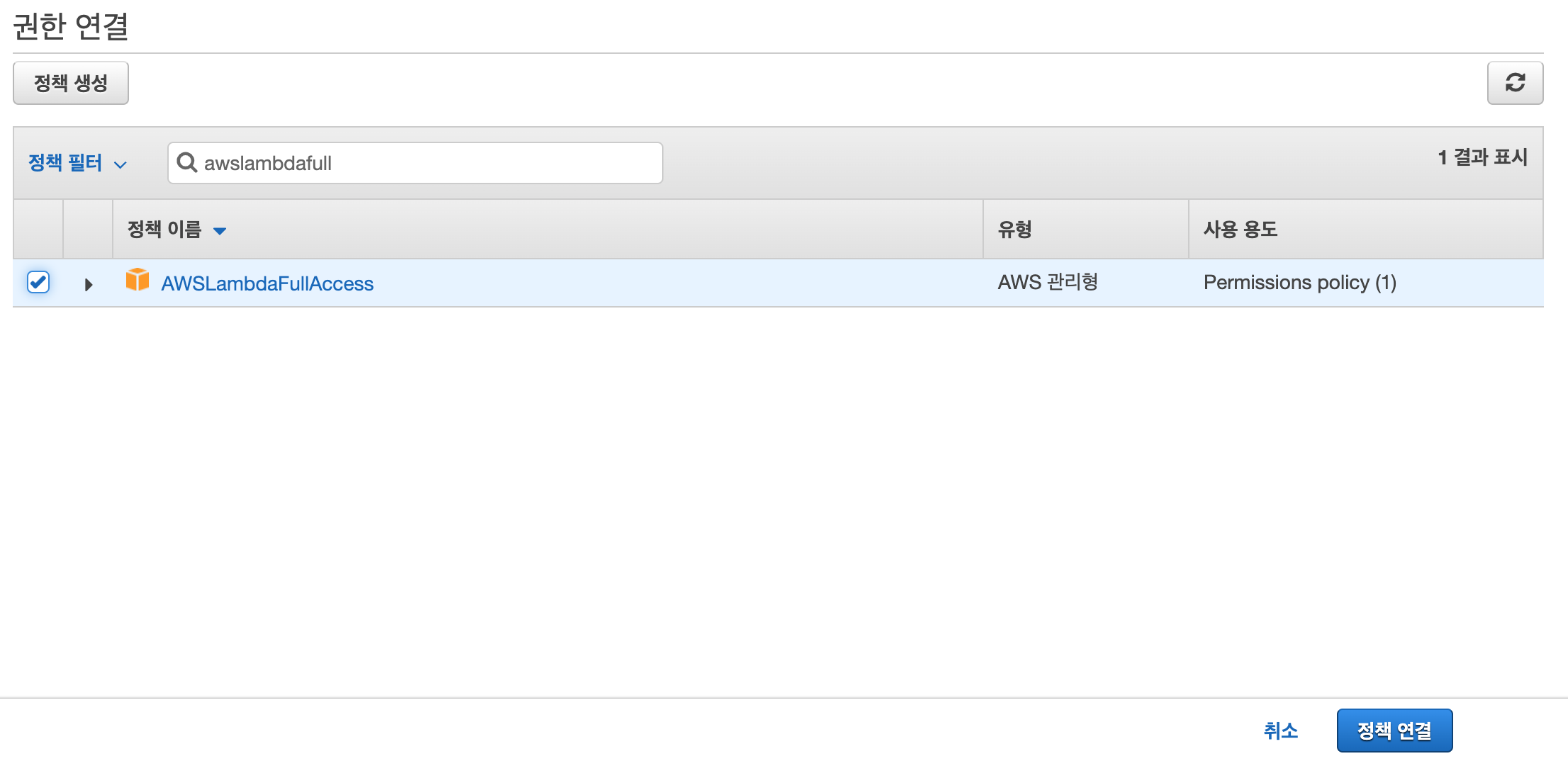
권한이 추가된 것을 확인할 수 있다.
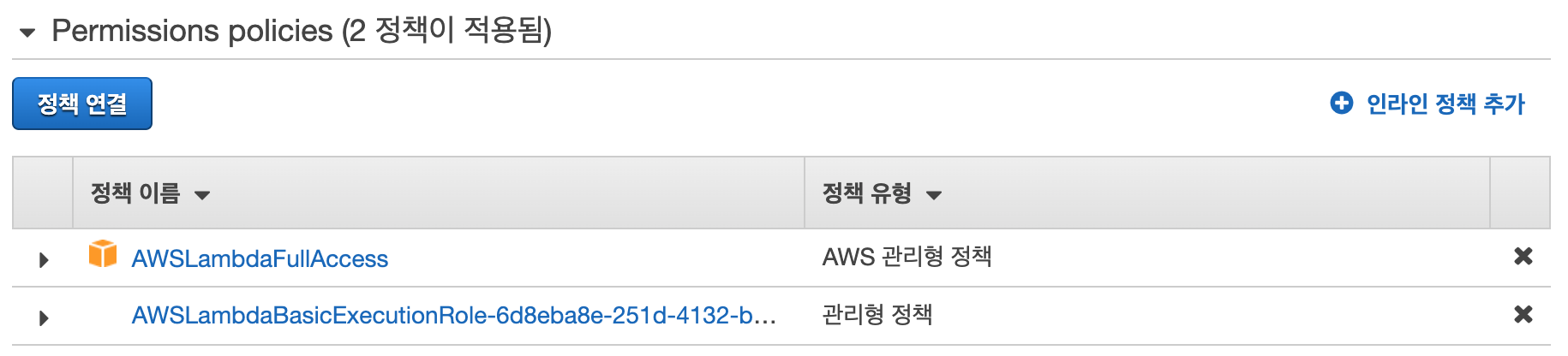
이제 데이터를 DynamoDB에 저장하는 Lambda 함수를 생성하고, 원래 Lambda에서 호출하는 코드를 삽입해야 한다. 이 내용에 대해서는 추후 추가하겠다.
데이터를 말풍선 형태에 맞게 보내기
카카오톡에서 사용자가 비틀즈라는 메시지 request를 보내면, 아래의 json 형태로 전달된다.
{
"intent": {
"id": "qqz5oy80luysrtiq4ck4ql4h",
"name": "블록 이름"
},
"userRequest": {
"timezone": "Asia/Seoul",
"params": {
"ignoreMe": "true"
},
"block": {
"id": "qqz5oy80luysrtiq4ck4ql4h",
"name": "블록 이름"
},
"utterance": "비틀즈\n",
"lang": null,
"user": {
"id": "363763",
"type": "accountId",
"properties": {}
}
},
"bot": {
"id": "5ec3be532ca48c00011f5300",
"name": "봇 이름"
},
"action": {
"name": "la6nkw2a2r",
"clientExtra": null,
"params": {
"group": "비틀즈"
},
"id": "3tllk8vhdoirf6bbkbl5k3co",
"detailParams": {
"artist_name": {
"origin": "비틀즈",
"value": "비틀즈",
"groupName": ""
}
}
}
}
지난 글에서 엔티티를 이용하여 사용자 발화에서 파라미터를 추출하는 내용에 다루었다. 이 파라미터는 위 json에서 action > params에 담기게 된다. 이걸 Search API 검색어로 사용해도 되지만, 문제는 항상 이런 파라미터가 생기지 않는다는 것이다. 레드벨벳을 검색하기 위해 레드벨벳이나 레드벨을 입력하면 생기지만, 레드를 입력하면 생기지 않는다.
이를 위해 파라미터 대신 사용자 발화를 그대로 검색어로 사용하려고 한다. 사용자 발화는 userRequest > utterance에 담긴다. 줄을 바꿔서 입력하지 않아도 뒤에 \n이 붙어서, .rstrip() 메소드로 이를 제거하고 사용해야 한다.
데이터 처리 로직
여기서는 로직을 보여주기 위한 핵심 코드 부분만 소개하려고 한다. 전체 코드는 Github에 올려 놓았다. 에러 처리를 위한 부분 때문에 여기에 소개한 코드와 조금 다를 수 있다.
카카오톡 사용자에게 아티스트 관련 정보를 주기 위한 데이터 처리 과정은 다음과 같다.
- 위에서 만든 MySQL의
artists테이블에 유저의 발화와 일치하는 아티스트가 있을 경우 해당 데이터 가져옴- 없을 경우, Search API에서 유저의 발화를 검색어로 하여 나오는 검색 결과를 리턴하고 MySQL에 저장
- 리턴받은 아티스트의 ID를 바탕으로
artist_genres테이블의 장르들 리턴 - 리턴받은 아티스트의 ID를 바탕으로
top_tracks데이터 리턴- 이미 DynamoDB에 저장되어 있는 아티스트면 DB에서 가져오고, 새로운 아티스트면 API 결과 리턴
- API 호출시 상위 3개 검색 결과 사용
- ListCard 타입 메시지에서 제목은
artists테이블의name, 이미지는artists테이블의image_url을 사용하고top_tracks의 각 트랙을 리스트로 보여줌- 버튼을 누르면 YouTube의 해당 아티스트 검색 결과 창으로 연결되게 하여, 아티스트의 다른 노래나 영상들도 볼 수 있게 해 줌. Spotify 링크를 사용해도 되지만, 국내 사용자가 별로 없으므로 범용적인 YouTube 링크를 사용
# 사용자 발화와 일치하는 아티스트가 DB에 없을 경우, Search API로 찾는 함수
def search_artist(cursor, artist_name):
headers = get_headers(client_id, client_secret)
params = {
"q": artist_name,
"type": "artist",
"limit": "1"
}
r = requests.get("https://api.spotify.com/v1/search", params=params, headers=headers)
raw = json.loads(r.text)
artist_raw = raw['artists']['items'][0]
# 수정된 쿼리 -> 검색 결과로 나온 아티스트가 MySQL에 있는지 확인
query = 'select id, name, image_url from artists where name = "{}"'.format(artist_raw['name'])
cursor.execute(query)
db_result = cursor.fetchall()
# 이미 있는 데이터면, DB 데이터를 변수로 할당하고 나감
if len(db_result) > 0:
globals()['raw'] = db_result
return
# DB에 없는 데이터면, DB에 저장해야 함
artist = {
'id': artist_raw['id'],
'name': artist_raw['name'],
'followers': artist_raw['followers']['total'],
'popularity': artist_raw['popularity'],
'url': artist_raw['external_urls']['spotify'],
'image_url': artist_raw['images'][0]['url']
}
# 이제 artists 테이블에 데이터 삽입
# insert_row는 MySQL에 데이터 삽입하는 함수
insert_row(cursor, artist, 'artists')
conn.commit()
# invoke_lambda는 다른 lambda function(top-tracks) 사용하는 함수
# top-tracks: DynamoDB에 Top Tracks 저장하는 lambda function
r = invoke_lambda('top-tracks', payload={'artist_id': artist_raw['id']})
### 메시지 응답 처리
temp = []
# 1. SimpleText: 아티스트 관련 안내
temp_text = {
"simpleText": {
"text": "{}의 노래를 들어보세요.".format(artist_raw['name'])
}
}
temp.append(temp_text)
# 2. SimpleText: DB에 데이터 추가하는 시간이 걸리므로, 이와 관련한 안내 메시지도 보냄
temp_text = {
"simpleText": {
"text": "아티스트가 추가되었습니다. 처리 시간 동안 기다려주셔서 감사합니다."
}
}
temp.append(temp_text)
# 3. ListCard
temp_list = {
"listCard": {
"header": {
"title": artist_raw['name'],
"imageUrl": temp_artist_url
},
# get_top_tracks는 아티스트의 id를 이용하여 DynamoDB나 API에서 해당 아티스트의 탑 트랙을 찾는 함수
# ListCard 형태에 맞게 리턴
"items": get_top_tracks(artist_raw['id']),
"buttons": [
{
"label": "다른 노래도 보기",
"action": "webLink",
"webLinkUrl": youtube_url
}
]
}
}
temp.append(temp_list)
return temp
# 메인 함수
def lambda_handler(event, context):
# 메시지 내용은 request의 'body'에 있음
request_body = json.loads(event['body'])
# 사용자 발화는 뒤에 \n이 붙어서, 제거
artist_name = request_body['userRequest']['utterance'].rstrip("\n")
query = 'select id, name, image_url from artists where name = "{}"'.format(artist_name)
cursor.execute(query)
globals()['raw'] = cursor.fetchall()
# 사용자 발화와 일치하는 아티스트가 DB에 없을 경우 DB에 추가하는 작업
if len(raw) == 0:
search_result = search_artist(cursor, artist_name)
# 새로운 데이터가 추가되었을 경우의 메시지 형태
if search_result:
result = {
"version": "2.0",
"template": {
"outputs": search_result
}
}
return {
'statusCode':200,
'body': json.dumps(result),
'headers': {
'Access-Control-Allow-Origin': '*',
}
}
# 사용자 발화와 일치하는 아티스트가 DB에 있을 경우
artist_id, db_artist_name, image_url = raw[0]
youtube_url = 'https://www.youtube.com/results?search_query={}'.format(db_artist_name.replace(' ', '+'))
# 장르 담기
query = """
select t2.genre from artists t1 join artist_genres t2 on t2.artist_id = t1.id
where t1.name = '{}'
""".format(db_artist_name)
cursor.execute(query)
genres = []
for (genre, ) in cursor.fetchall():
genres.append(genre)
# 최종 메시지
result = {
"version": "2.0",
"template": {
"outputs": [
# 1. SimpleText: 아티스트 관련 안내
{
"simpleText": {
"text": "{}의 노래를 들어보세요.".format(db_artist_name)
}
},
# 2. ListCard: top tracks
{
"listCard": {
"header": {
"title": temp_artist_name,
"imageUrl": image_url
},
# get_top_tracks는 아티스트의 id를 이용하여 DynamoDB나 API에서 해당 아티스트의 탑 트랙을 찾는 함수
# ListCard 형태에 맞게 리턴
"items": get_top_tracks(artist_id),
"buttons": [
{
"label": "다른 노래도 보기",
"action": "webLink",
"webLinkUrl": youtube_url
}
]
}
},
]
}
}
# 메시지 리턴
return {
'statusCode':200,
'body': json.dumps(result),
'headers': {
'Access-Control-Allow-Origin': '*',
}
}
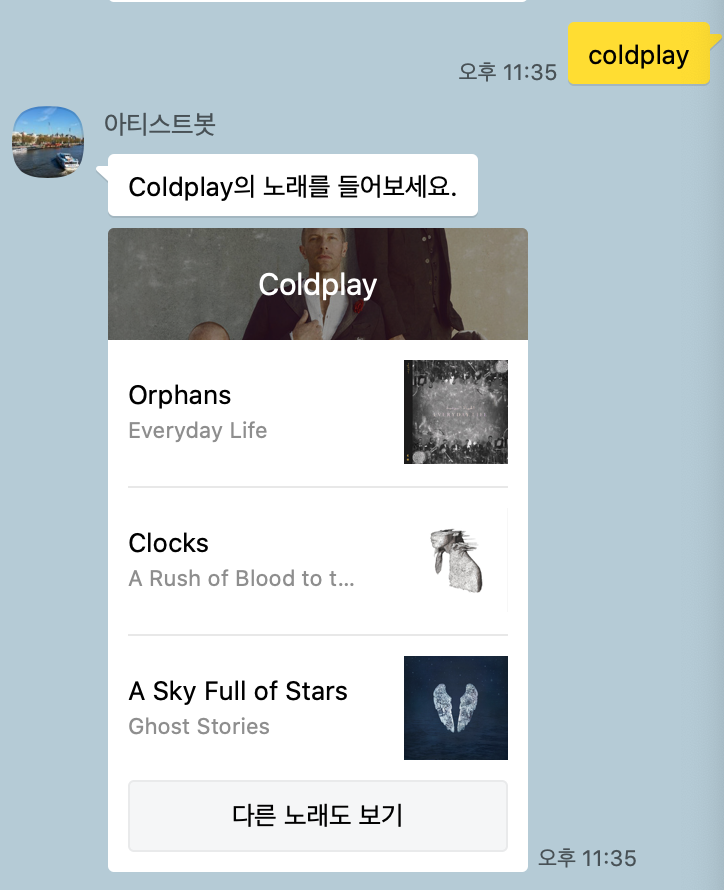
최종 결과
이미 DB에 있는 아티스트의 경우는 다음과 같다.
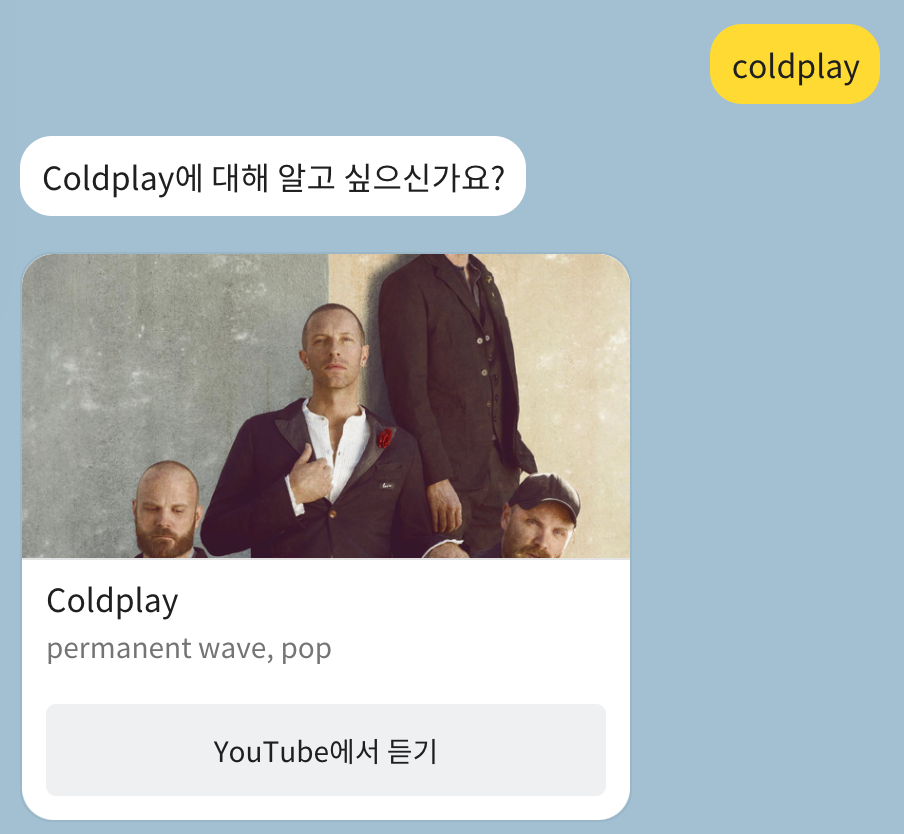
DB에 없는 아티스트는 다음과 같다.
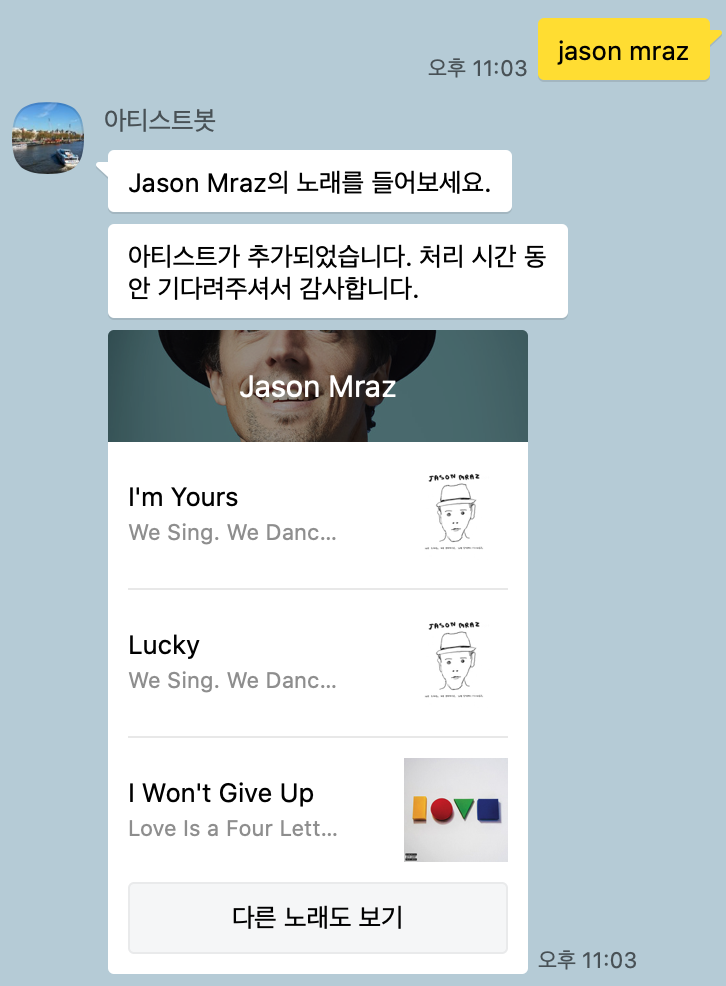
원래는 아래와 같이 BasicCard의 형태로 아티스트 이름과 장르들을 보여주려고 하였으나, 정보가 너무 적어 효용성이 없는 것 같아서 Top Tracks를 보여주는 것으로 변경하였다.
이렇게 되면 장르 테이블이 쓸모가 없다- 장르 테이블은 추후 사용 여부를 결정하려고 한다. 관련 아티스트를 찾는 데 사용할 수 있을 것 같다.
마무리하며
사용자 발화와 일치하는 아티스트가 DB에 있을 때와 아닐 때를 구분하여 코드를 작성했다. 그런데 일치하지 않을 경우 DB에 데이터 추가를 위한 시간이 걸리므로, 처리 시간이 걸리지 않는 메시지(예: 안내 메시지)가 불필요하게 대기하게 된다. 사용자 입장에서는 제대로 처리가 되고 있는지 알 수가 없다. 이에 대한 해결 방법을 찾지 못해서 일단 하나의 함수에서 여러 메시지를 동시에 보내 주었다. 각 메시지를 각각의 Lambda 함수로 사용하여 사용자에게 보내 주는 등 해결 방법을 찾아봐야겠다.
결과만 놓고 보면, 그냥 YouTube에서 아티스트 이름으로 검색하는 것이 나을 수도 있다. 하지만 이 과정은 관련 아티스트 정보를 제공해 주기 위한 전초과정이라 보면 된다. 멜론 등의 음원 서비스에서 노래를 추천해 주듯이, 카카오톡 챗봇으로 아티스트 및 노래를 추천해 주는 것이다.
다음 글에서 이에 대해 다루겠다.