
카카오톡 챗봇 개발기를 아래와 같이 시리즈로 포스팅하고 있다.
- 기본적인 환경설정 및 메시지 응답 테스트
- 입력한 아티스트의 정보 제공
- 관련 아티스트 및 노래 추천
지난 글에서 MySQL과 DynamoDB를 이용하여, 아티스트를 요청받으면 해당 아티스트에 대한 인기 트랙 정보를 응답해 주는 내용을 다루었다.
이번 글에서는 Amazon S3와 Athena까지 활용하여 관련 아티스트를 추천해 줄 것이다. 아티스트별 인기 트랙들(top_tracks)의 음원 정보(audio_features)를 이용하여 아티스트 간의 유사도(Euclidean Distance)를 구하고, 사용자가 입력받은 아티스트와 유사도가 큰(=거리가 작은) 아티스트를 응답해 줄 것이다.
목차는 다음과 같다.
- 아티스트 데이터 가져오기
- 아티스트별 top_tracks와 트랙별 audio_features를 S3에 저장
- S3에 저장한 데이터를 Athena를 통해 쿼리하여 아티스트 간 거리 계산
- 배치 처리를 통한 자동화
- 최종 결과 확인
중간 중간에 코드를 첨부했는데, 전체 코드는 Github에 올려 놓았다. 1-2번 과정은 ttandaudio_to_s3.py, 3번 과정은 related_artists.py에서 확인할 수 있다.
아티스트 데이터 가져오기
챗봇에서 새로운 아티스트를 입력할 때마다 MySQL의 artists 테이블에 추가되고 있다. 배치 처리 시점에서의 데이터를 가져온다.
import pymysql
# connect MySQL
try:
conn = pymysql.connect(host, user=username, passwd=password, db=database, port=port, use_unicode=True, charset='utf8')
cursor = conn.cursor()
except:
logging.error("could not connect to rds")
sys.exit(1)
cursor.execute("SELECT id, name FROM artists")
for (artist_id, name) in cursor.fetchall():
"""
top_tracks 데이터 처리할 부분
"""
아티스트별 top_tracks와 트랙별 audio_features를 S3에 저장
Amazon S3에 데이터를 저장한다. 절차를 다시 정리하면 아래와 같다.
- 위에서 얻은 아티스트별 id를 바탕으로 Spotify API에서 해당 아티스트의
top_tracks데이터 쿼리, S3에 저장 top_tracks에서 얻은 트랙별 id를 바탕으로 Spotify API에서 해당 트랙의audio_features데이터 쿼리, S3에 저장
코드를 소개하기 전에, S3에 저장하는 과정에서 몇 가지 특징이 있다.
- API 쿼리 결과는
json형태로 반환된다. - S3에 저장할 때 json을 그대로 저장하는 대신
parquet형식으로 저장할 것이다. - parquet은 컬럼 기반 포맷 으로, 압축률이 높고 일부 컬럼만 읽어 들일 수 있어 처리량을 줄일 수 있다. 자세한 장점에 대해서는 Apache Spark에서 컬럼 기반 저장 포맷 Parquet(파케이) 제대로 활용하기에서 볼 수 있다.
- S3에 저장한 데이터를
Athena라는 Presto 기반 쿼리 엔진을 통해 쿼리할 것인데, Athena는 parquet 형태의 데이터에서 json처럼 nested field를 지원하지 않는다.- nested field는
{"tracks": [{"album": "num1"}, {"album": "num2"}]}처럼 계층 구조를 가진 컬럼을 말한다.
- nested field는
- 따라서 계층 구조를 가지고 있는 API 데이터에서 필요한 컬럼만 추출하여 flat 한 형태로 변환할 것이다.
- 계층 구조를 가진 컬럼을 찾아서 추출할 때
jsonpath라는 python 라이브러리를 사용한다.
- 계층 구조를 가진 컬럼을 찾아서 추출할 때
먼저 아티스트별 id를 이용하여 top_tracks 데이터를 쿼리하고, 하나의 객체(top_tracks)에 모은다.
import json, jsonpath
# top_track_keys: API 데이터에서 필요한 컬럼의 path 저장
# 예: external_url은 API 데이터의 각 트랙 결과의 ['external_urls']['spotify']에 위치함
top_track_keys = {
"id": "id", # track id
"name": "name",
"popularity": "popularity",
"external_url": "external_urls.spotify",
"album_name": "album.name",
"image_url": "album.images[1].url"
# url, image_url은 nested 구조. 안의 flat한 값만 가져 옴
}
top_tracks = [] # 전체 데이터 모으기
for (artist_id, name) in cursor.fetchall():
URL = "https://api.spotify.com/v1/artists/{}/top-tracks".format(artist_id)
params = {
'country': 'US'
}
r = requests.get(URL, params=params, headers=headers)
raw = json.loads(r.text)
for i in raw['tracks']: # i는 하나의 트랙
top_track = {}
for k, v in top_track_keys.items():
value = jsonpath.jsonpath(i, v)
# 해당 위치에 데이터가 없으면 False를 리턴(bool type). 이럴 경우 다음 컬럼으로 넘어감
if type(value) == bool:
continue
top_track.update({k: value}) # path(v)에 맞게 API에서 찾아 그 위치의 value를 가져옴
top_track.update({'artist_id': artist_id}) # key 값을 위해 아티스트 id도 넣어줌
top_tracks.append(top_track)
모은 데이터를 parquet 파일로 저장하고, 이 파일을 최종적으로 S3에 저장한다.
- 여기서
track_ids는audio_features데이터를 쿼리할 때 필요한 트랙 id들을 담고 있다. pyarrow라는 엔진을 사용한다. 이를 위해pip install pyarrow로 라이브러리 설치가 필요하다.- compression은 압축 방식이다. 데이터를 압축하여 저장 용량은 줄인다.
import pandas as pd
# 뒤의 audio_features에 사용할 track_ids 변수 생성
track_ids = [i['id'][0] for i in top_tracks] # jsonpath 사용하면 ['id'] 형태로 저장 -> [0]으로 벗겨야 함
top_tracks = pd.DataFrame(top_tracks)
top_tracks.to_parquet('top-tracks.parquet', engine='pyarrow', compression='snappy')
# S3에 저장
s3 = boto3.resource('s3')
dt = datetime.utcnow().strftime('%Y-%m-%d') # UTC 기준 현재 시간으로. "2020-08-01" 형태
s3_object = s3.Object('{bucket_name}', 'top-tracks/dt={}/top_tracks.parquet'.format(dt)) # 새로운 폴더(파티션)가 생성이 되는 것
data = open('top-tracks.parquet', 'rb')
s3_object.put(Body=data)
top_tracks 데이터를 S3에 저장하는 작업은 여기까지이다. audio_features 데이터도 같은 과정으로 진행한다. 다만 audio_features는 top_tracks와 달리 nested field가 없기 때문에, jsonpath 라이브러리를 사용할 필요 없이 raw data를 그대로 저장하면 된다.
분량상 audio_features 데이터에 관한 코드는 생략한다. Github의 ttandaudio_to_s3.py에서 전체 코드를 올려 놓았다.
DynamoDB에 top_tracks 데이터 업데이트
새롭게 얻은 top_tracks 데이터를 DynamoDB의 top_tracks 테이블에 업데이트하여, 챗봇에 최근 많이 들은 인기 트랙을 제공해 줄 것이다.
S3에 저장한 데이터를 DynamoDB로 Load 할 수 있으나, Amazon EMR 인스턴스가 필요하다. 프리 티어도 아닐 뿐더러, EC2처럼 인스턴스를 켜 둔 시간에 비례하여 요금이 산정되기 때문에, 2일 정도밖에 안 썼는데도 수십 달러의 요금 폭탄을 맞은 적이 있다. 그래서 API 결과를 바로 DynamoDB에 업데이트하기로 했다.
DB 데이터를 업데이트하려면 새로운 key(트랙 id)를 가진 데이터는 삽입하고, 기존에 있던 key를 가진 행의 데이터는 업데이트(insert & update)해야 한다. boto3의 put_item 메소드를 이용하여 이 기능을 구현할 수 있다!

이 때 주의해야 할 점이 있다. DynamoDB에 담긴 데이터를 python 코드를 통해 아래와 같이 한 레코드씩 업데이트하면, 프로비전 용량 (테이블 생성 시 미리 정해 둔 읽기/쓰기 용량)을 초과하여 해당 레코드는 작업이 완료되지 않게 된다.
table = dynamodb.Table('top_tracks')
# data['tracks']: API 쿼리한 트랙별 top_tracks 데이터
for track in data['tracks']:
temp = {
'artist_id': artist_id
}
temp.update(track) # 원래 데이터 + artist_id까지 DB에 삽입
table.put_item(
Item=temp
)
프로비전 용량을 초과하지 않고 정상적으로 모든 레코드를 업데이트하려면 batch_writer를 이용해야 한다. batch_writer는 처리 속도가 빠르며, 서비스에 요청하는 횟수를 줄일 수 있다.
with table.batch_writer() as batch:
for track in data['tracks']:
temp = {
'artist_id': artist_id
}
temp.update(track)
batch.put_item(
Item=temp
)
참고로, 레코드를 삭제 할 때도 똑같이 적용된다. 아래와 같이 한 레코드씩 삭제할 경우 프로비전 용량을 초과한다.
table = dynamodb.Table('top_tracks')
scan = table.scan() # 테이블 전체 데이터 가져옴
for item in scan['Items']:
table.delete_item(
Key={
'artist_id': item['artist_id'],
'id': item['id']
}
)
아래와 같이 batch_writer를 사용하면 프로비전 용량 초과를 줄일 수 있다.
with table.batch_writer() as batch:
for item in scan['Items']:
batch.delete_item(
Key={
'artist_id':item['artist_id'],
'id': item['id']
}
)
- 참고로 DynamoDB에서 레코드를 삭제할 때에는 파티션 키(내 경우는
artist_id), 정렬 키(내 경우는id) 조건을 모두 주어야 한다.
DynamoDB에 top_tracks 데이터를 업데이트하는 작업은 데이터를 S3에 저장하는 스크립트에서 하지 않았다. Lambda 함수를 invoke 하여 비동기 방식으로 처리 되도록 하였다. 프리 티어 범위에서 사용할 수 있는 프로비전 용량이 넉넉하지 않기 때문에, 동기 방식으로 처리할 경우 모든 데이터를 업데이트하면 시간이 오래 걸리기 때문이다.
resp = invoke_lambda('top-tracks', payload={
'artist_name': name, # 로그 용도로 이름까지 보냄
'artist_id': artist_id,
'data': raw
})
해당 Lambda 함수(top-tracks)에서 batch.put_item을 이용하여, 프로비전 용량을 초과하지 않도록 했다.
S3에 저장한 데이터를 Athena를 통해 쿼리하여 아티스트 간 거리 계산
Amazon Athena는 S3에 저장된 데이터를 분석할 수 있는 대화식 쿼리 서비스이다. 표준 SQL을 사용하여 쿼리할 수 있다. 웹 콘솔에서도 쿼리할 수 있지만, 스크립트를 통해 자동화할 것이기 때문에 python에서 쿼리하는 방법을 소개한다. 전체 코드보다는 데이터 처리 방법 위주로 다루고자 한다.
1. Athena에서 S3 데이터 쿼리
먼저 S3 데이터로 top_tracks, audio_features 테이블을 생성한다. 쿼리에 테이블 형태, S3 주소, 압축 형식 등을 명시해 준다. 아래와 같이 python 스크립트를 통해 쿼리를 실행할 수 있다.
import boto3
def query_athena(query, athena):
response = athena.start_query_execution(
QueryString=query,
QueryExecutionContext={
'Database': 'Athena 상에서 Database 이름'
},
ResultConfiguration={
# 쿼리 결과를 저장하는 위치 지정 (데이터의 위치와 다르게!)
'OutputLocation': "s3://{bucket_name}/{folder_name}/",
'EncryptionConfiguration': {
'EncryptionOption': 'SSE_S3'
}
}
)
return response
athena = boto3.client('athena')
query = """
create external table if not exists top_tracks(
id string,
artist_id string,
name string,
album_name string,
popularity int,
image_url string
) partitioned by (dt string)
stored as parquet location 's3://{bucket_name}/{folder_name}' tblproperties("parquet.compress" = "snappy")
"""
r = query_athena(query, athena)
S3에 저장한 파일의 주소는 {bucket_name}/{folder_name}/dt={}/top_tracks.parquet 형식이다. dt={}을 넣음으로 데이터에서 파티션이 자동으로 적용되도록 했다. 파티션 단위로 구성하면 처리 속도를 빠르게 할 수 있으며, DML 쿼리시 where dt={날짜} 구문으로 필요한 날짜의 데이터만 가져올 수 있다. year={}/month={}/day={} 처럼 여러 개의 파티션 컬럼을 지정할 수도 있다.
단 아래 쿼리까지 반드시 실행해야 파티션이 적용된다.
msck repair table top_tracks
audio_features 데이터도 위와 같이 형식에 맞게 테이블을 생성하면 된다.
2. 아티스트 간 거리 계산
두 데이터를 사용할 것이다.
- top_tracks 데이터에는 트랙(노래)별 id와 아티스트 id가 있다.
- audio_features 데이터에는
danceability,acousticness,instrumentalness등 음원의 특성을 요약한 수치들이 있다.
챗봇에서 관련 아티스트를 추천해 주는 과정은 다음과 같다.
- 아티스트별로 인기 트랙의 danceability 평균, acousticness 평균, instrumentalness 평균 등
audio_features에 있는 수치별 평균값 을 구한다. - 이를 바탕으로 아티스트들 간의 Euclidean Distance를 계산 하여 MySQL에 저장한다.
- 요청받은 아티스트와 Euclidean Distance가 가장 가까운 아티스트를 제공 한다.
Euclidean Distance는 우리가 수학적으로 흔히 아는 거리를 말한다. 아래와 같이 각 요소에 대하여 차이의 제곱들을 더해준 후 제곱근을 씌운다.

트랙의 수치 자체가 아닌 수치들의 평균 을 사용하는 것이기 때문에 정보를 많이 잃어버리게 되지만, 프로토타입으로 일단은 간단한 방법을 이용했다.
아티스트들 간의 거리를 계산하여 MySQL의 related_artists 테이블에 삽입했다. 그리고 Lambda 함수의 코드에 요청받은 아티스트와 거리가 가장 가까운 아티스트 3개를 제공하는 부분을 추가했다.
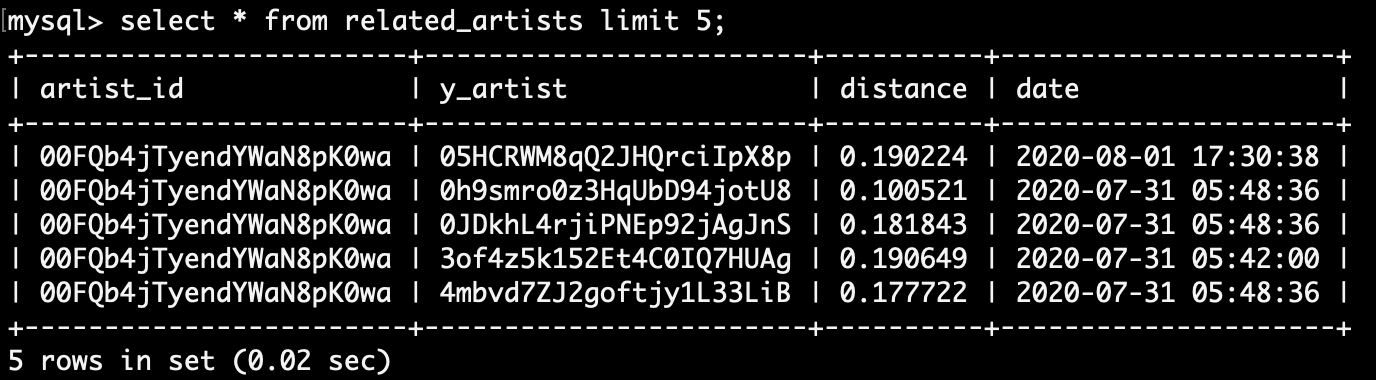
- 이 테이블은
artist_id,y_artist두 개의 primary key가 있다. 두 아티스트 간의 관계 에 관한 테이블이기 때문이다. - 지금까지
MySQL이나DynamoDB에 데이터를 추가할 때 적용한 사항인데, 새로운 키는 삽입하고 기존에 있던 키는 업데이트(insert & update)하도록 했다. DynamoDB에서는 위에서 언급했듯이put_item메소드를 사용하고, SQL에서는 아래와 같이ON DUPLICATE KEY UPDATE구문을 사용하면 된다.INSERT INTO related_artists(artist_id, y_artist, distance) VALUES('00FQb4jTyendYWaN8pK0wa', '05HCRWM8qQ2JHQrciIpX8p', 0.190224) ON DUPLICATE KEY UPDATE artist_id='00FQb4jTyendYWaN8pK0wa', y_artist='05HCRWM8qQ2JHQrciIpX8p', distance=0.190224;
여기까지의 과정을 매일 밤 자동적으로 처리되도록 할 것이다. 실시간 처리가 아니고 하루 1번만 하기 때문에, 챗봇에서 새로 추가된 아티스트는 관련 아티스트가 바로 제공되진 않는다. 이 부분은 추후 개선해야 한다.
배치 처리를 통한 자동화
리눅스 crontab을 통해 자동화할 것이다.
- 이와 관련하여, AWS에서 배치 처리하는 방법은 Amazon EC2와 리눅스 crontab을 이용한 배치 처리에 적어 놓았다.
터미널에서 아래와 같이 입력하여, ttandaudio_to_s3.py, related_artists.py 파일을 EC2로 복사한다.
scp -i key-pair.pem ttandaudio_to_s3.py ec2-user@{퍼블릭 DNS}:~/
scp -i key-pair.pem related_artists.py ec2-user@{퍼블릭 DNS}:~/
EC2로 들어간다.
ssh -i key-pair.pem ec2-user@{퍼블릭 DNS}
crontab -e 명령어를 입력하여, 아래와 같이 자동화할 파일 목록을 써 준다. 소요 시간을 고려하여 10분 간격으로 두었다. 한국 시간 기준으로 두 파일을 각각 새벽 2시 20분(UTC 17:20 + 9시간), 2시 30분(UTC 17:30 + 9시간)에 실행되도록 했다.
20 17 * * * /usr/bin/python3 /home/ec2-user/ttandaudio_to_s3.py
30 17 * * * /usr/bin/python3 /home/ec2-user/related_artists.py
최종 결과 확인
아래와 같이 검색한 아티스트와 관련 아티스트들을 가로로 넘기면서 볼 수 있다. 한 장의 카드가 아닌 Carousel을 적용하여 여러 장의 카드를 같이 볼 수 있도록 했다.
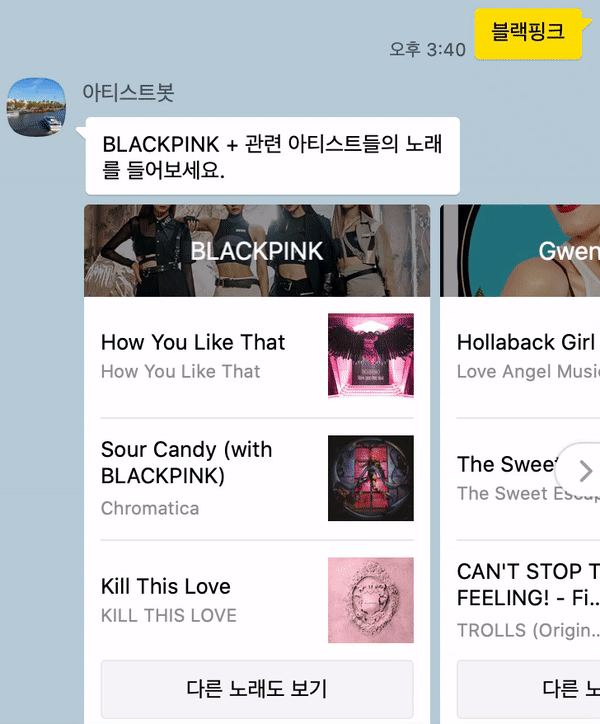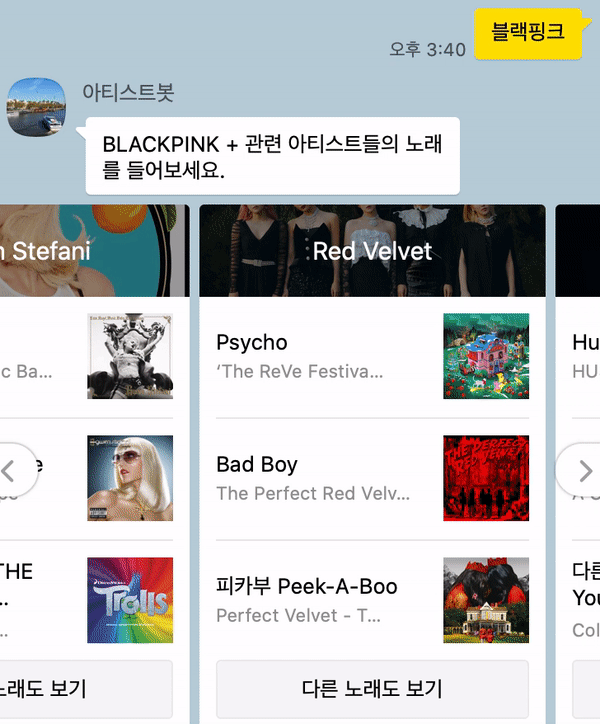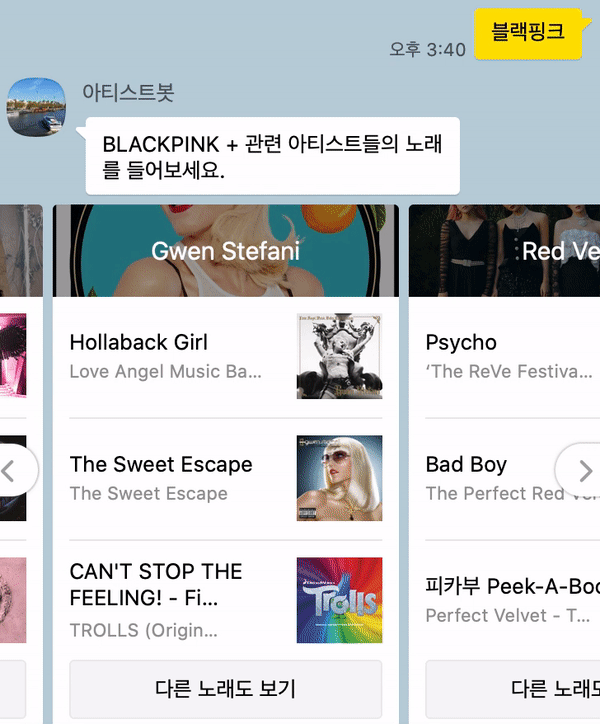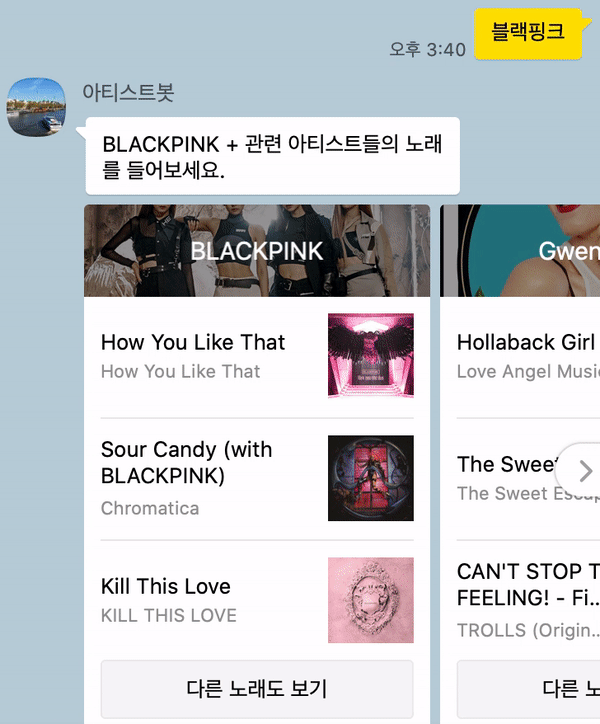
- 단순히 음원 수치를 이용한 것이지만, 여자 아이돌 그룹의 경우 관련 아티스트로 여자 아이돌 그룹이 나오는 것을 확인할 수 있다! 음악 스타일이 비슷한 것이
audio_features수치상으로도 나타나는 것으로 보인다. - 추가 사항: 2020년 10월 27일 현재, 아티스트 이름과 같이 표시되는 이미지가 더 이상 적용되지 않는다. 아티스트 카드별로 확실히 구분되는 느낌이 있어서 좋았는데 아쉬운 부분이다..
마무리하며
2편을 작성한 이후로 2달 가까이 걸렸다. 내용이 적은 것은 아니었지만 나의 게으름이 한 몫 했다. 프로토타입을 우선 개발하기 위해 Euclidean Distance를 계산하는 단순한 방법을 사용했지만, 이후에는 Cosine Similarity나 다른 추천 알고리즘을 적용해 보려고 한다.
머신러닝 알고리즘을 적용하려면 수천 개 이상의 아티스트 데이터가 필요하다. 그만큼의 Spotify 아티스트 ID가 필요한데, 현재 DB에 수집된 아티스트는 800개 정도이기 때문에 어떻게 수집해야 할지 고민 중이다. 아티스트별이 아닌, 트랙별 데이터를 이용할 수도 있다. 학습을 위해 Spotify 말고 아예 다른 데이터를 사용하는 것도 고려 중이다. 추천 알고리즘에 대한 공부도 더 필요하다.
긴 글 읽어주셔서 감사합니다.