
맥미니도 산 겸 카카오톡 챗봇을 업데이트 해 보았다. 2020년에 AWS Lambda를 이용한 Serverless 카카오톡 챗봇 만들기 시리즈를 쓴 적이 있는데, AWS에서 제공하는 DB 서비스의 경우 비용 부담이 있거나(RDS), 프리 티어 범위에서 성능이 너무 제한적이었다(DynamoDB).
맥미니 서버를 산 이유 중 하나이기도 한데, 내 로컬 서버에서 자유롭게 DB를 운영하고 챗봇 데이터도 이 DB를 이용하고자 했다. 그래서 이번 글에서는 로컬 MySQL을 사용한 부분과 소소한 챗봇 변경 사항에 대해서 다루고자 한다. 이제 서버는 클라우드, DB는 로컬을 이용하는 하이브리드 서비스가 되었다.
참고로 MySQL 세팅 방법은 MySQL 원격 접속 허용하기 글에 적어 놓았다.
목차는 다음과 같다.
1. DynamoDB 데이터 백업
Amazon DynamoDB에 있는 데이터를 저장한다.
사실 이 데이터는 Spotify API 결과를 저장한 것에 불과하다. 프리 티어로 쓸 수 있는 DynamoDB의 경우 입출력 용량이 매우 제한적이기 때문에, 모든 데이터를 출력하기가 힘들다. 그래서 필요한 데이터만 가져오기로 하고, 나머지는 API 데이터를 다시 수집하기로 했다.
현재 DynamoDB 데이터 모델은 다음과 같다.
artists테이블: 987개 아티스트 정보 (987행)top_tracks테이블: 987개 아티스트의 인기 트랙 (12,933행)related_artists테이블: 987개 아티스트 서로의 유사도 (13,490행)
artists 테이블 외 2개의 테이블은 용량이 15MB 수준으로 큰 양은 아니지만, DynamoDB의 말도 안 되는 성능 제한으로 인해 한 번에 모든 데이터를 받아오기 힘들다. 그래서 artists 테이블만 가져오기로 했다.
import boto3
# connect DynamoDB
try:
dynamodb = boto3.resource('dynamodb', region_name='ap-northeast-2', endpoint_url='http://dynamodb.ap-northeast-2.amazonaws.com')
except:
logging.error('could not connect to dynamodb')
sys.exit(1)
table = dynamodb.Table('artists')
artists = table.scan()
artists['Items'] # 데이터 확인
다른 테이블은 API 데이터를 다시 수집하기로 했으니, 다음으로 넘어간다.
2. Spotify API 데이터 수집
새로 수집할 Spotify API 데이터 목록은 다음과 같다.
1. Top Tracks
- API 설명 문서
- 한 아티스트의 인기 트랙
- key: artist id
아래와 같이 트랙별로 필요한 컬럼들만 수집한다. 챗봇에 아티스트당 3개의 트랙을 표시할 것이므로, 3개씩만 수집한다.
def get_top_tracks_api(artist_id):
URL = "https://api.spotify.com/v1/artists/{}/top-tracks".format(artist_id)
params = {
'country': 'US'
}
headers = get_headers(client_id, client_secret)
r = requests.get(URL, params=params, headers=headers)
raw = json.loads(r.text)
top_track_items = []
for ele in raw['tracks'][:3]:
temp_dic = {
"id": ele['id'],
"artist_id": artist_id,
"name": ele['name'],
"popularity": ele['popularity'],
"album_name": ele['album']['name'],
"image_url": ele['album']['images'][1]['url'], # images는 같은 앨범 이미지에 대해서 크기별로 넣어 놓은 것. 1이 적당한 사이즈(300x300)라 고름
}
top_track_items.append(temp_dic)
return top_track_items
id: 트랙 idartist_id: 아티스트 idnamepopularity: 인기도album_name: 해당 트랙 앨범명image_url: 트랙 앨범 이미지(챗봇 표시용)
2. Related Artists
- API 설명 문서
- 한 아티스트의 관련 아티스트들
- key: artist id
기존 챗봇 글에서 아티스트들의 Top Tracks 데이터를 이용하여 서로간의 거리를 계산하고, 관련 아티스트 데이터를 적재했었다. 그러나 이제는 Related Artists를 제공하여, 계산할 필요가 없어졌다. 해당 API에서 내가 계산했던 결과와 더 비슷한 아티스트를 제공하기 때문이다.
아래와 같이 아이브로 쿼리를 날려 보면, 유사한 걸그룹들이 나오는 것을 확인할 수 있다.
URL = "https://api.spotify.com/v1/artists/6RHTUrRF63xao58xh9FXYJ/related-artists" # IVE
headers = get_headers(client_id, client_secret)
r = requests.get(URL, headers=headers)
raw = json.loads(r.text)
for ele in raw['artists'][:10]:
print(ele['name'])
# NMIXX
# Kep1er
# IZ*ONE
# STAYC
# GOT the beat
# fromis_9
# Billlie
# LE SSERAFIM
# OH MY GIRL
# WJSN
아래와 같이 트랙별로 필요한 컬럼들만 수집한다. 챗봇에는 아티스트당 3개의 관련 아티스트를 표시할 것이지만, 여유롭게 10개씩 적재했다.
def get_related_artists_api(artist_id):
URL = "https://api.spotify.com/v1/artists/{}/related-artists".format(artist_id)
headers = get_headers(client_id, client_secret)
r = requests.get(URL, headers=headers)
raw = json.loads(r.text)
rel_artists = []
rank = 0
for ele in raw['artists'][:10]:
rank += 1
temp_dic = {
'artist_id': artist_id,
'related_id': ele['id'],
'rank_rel': rank
}
rel_artists.append(temp_dic)
return rel_artists
artist_id: 아티스트 idrelated_id: 관련 아티스트 idrank_rel: 연관도 순위 (API 기준)
이제 이 두 데이터를 DB에 적재할 것이다.
3. MySQL에 데이터 삽입
테이블 구조는 다음과 같다.
1. artists
create table artists (
id varchar(255) primary key,
name varchar(255),
followers int,
popularity int,
url varchar(255)
image_url varchar(255)
);
- 기존
DynamoDB데이터 기반
2. top_tracks
create table top_tracks (
id varchar(255) primary key,
artist_id varchar(255),
name varchar(255),
popularity int,
album_name varchar(255),
image_url varchar(255)
);
- 새로 수집
3. related_artists
create table related_artists (
artist_id varchar(255), -- 원래 artist id
related_id varchar(255), -- 연관 artist id (3개까지 쌓기)
rank_rel int, -- 순위(1~6)
primary key(artist_id, related_id)
);
- 새로 수집
- artists 테이블에 없는
related_id에 해당하는 아티스트는 artists 테이블에도 동시에 적재한다.
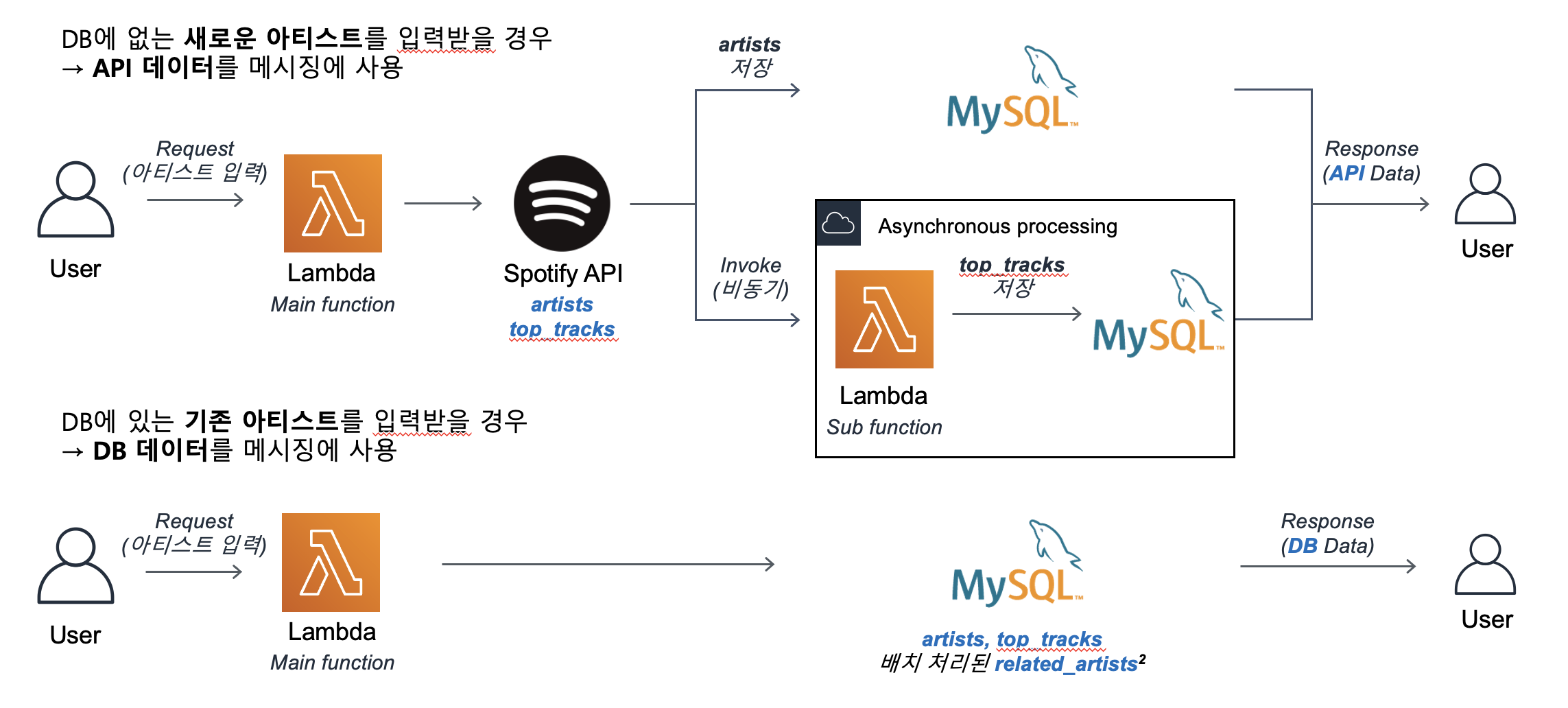
기존 아티스트의 정보를 위 3개 테이블에 넣었으며, 새로운 아티스트가 추가될 때에도 역시 3개 테이블에 적재된다.
4. 기능 개선 사항
기존에는 related_artists 데이터를 배치로 처리했다. 이럴 경우 다음 배치 주기까지 새로 추가된 아티스트의 연관 아티스트가 없게 되었다. 그래서 새로운 아티스트가 추가될 때마다 related_artists 데이터를 비동기로 추가했다. 이미 top_tracks 데이터를 새로 아티스트가 추가될 때마다 비동기로 추가하고 있었는데, 작업이 하나 더 생기게 된 것이다.
- AWS Lambda에서의 비동기 작업 방식에 대해서는 카카오톡 챗봇 개선 과정 글에 적어 놓았다.
- 챗봇 전체 코드는 Github에 올려 놓았다.
끝으로, 정말 별거 아니지만 취준때 만들어서 나름 애정이 가는 아티스트봇 한번 사용해 보세요.
마치며
맥미니를 사고 난 후 첫 작업이었다. DB 요금 제한이 없다 보니 자유롭게 데이터 작업을 할 수 있어서 좋았다. 작업은 12월 초에 했지만, 연말연시라는 핑계로 노느라 블로그 글을 쓰지 못했다. 3월 말까지 사이드 프로젝트를 하려고 한다. 틈틈이 진행해서 미루지 않고 마무리하고자 한다.